기본 정보
- 제목: ReAct: Synergizing Reasoning and Acting in Language Models
- 저자: Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
- 소속: Princeton University, Google Research
- 발표일: 2022년 10월 6일 (arXiv), 2023년 (ICLR 2023)
- arXiv: https://arxiv.org/abs/2210.03629
- 프로젝트: https://react-lm.github.io/
- 분야: Computation and Language, Artificial Intelligence
- 학회: ICLR 2023 (International Conference on Learning Representations)
연구 개요
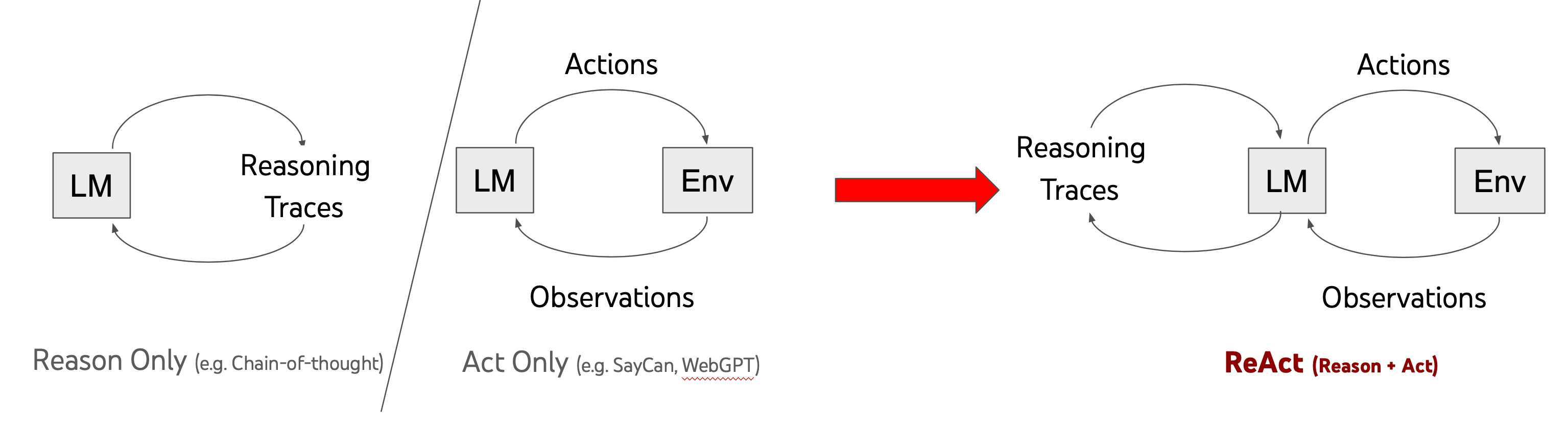
ReAct는 대규모 언어 모델에서 추론(Reasoning)과 행동(Acting)을 교차(interleaving)시켜 시너지 효과를 만드는 혁신적인 프레임워크입니다. 언어 모델이 사고 과정을 생성하면서 동시에 외부 도구와 상호작용하여 정보를 수집하고 작업을 수행할 수 있게 합니다. 이 접근법은 Chain-of-Thought(CoT) 추론의 한계인 환각(hallucination) 문제를 해결하고, 단순 행동 기반 에이전트의 추론 능력 부족 문제를 극복합니다.
핵심 개념
1. ReAct 패러다임
기존 접근법의 한계
추론 전용 접근법 (Chain-of-Thought)
- 내부 지식에만 의존
- 외부 정보에 접근 불가
- 사실 확인이 어려움
- 환각(hallucination) 문제 발생
행동 전용 접근법 (Act-only)
- 외부 환경과 상호작용 가능
- 추론 과정이 불투명
- 오류 발생 시 원인 파악 어려움
- 계획 수립 능력 부족
ReAct의 핵심 원리
추론과 행동의 통합
ReAct는 다음 두 가지를 교차시킵니다:
-
Thought (사고): 내부 추론 단계
- 현재 상황 분석
- 계획 수립 및 업데이트
- 정보 분해 및 추출
- 상식 추론
-
Action (행동): 외부 도구 호출
- 지식 베이스 검색
- 웹 API 호출
- 데이터베이스 조회
- 환경 조작
-
Observation (관찰): 행동 결과 수신
- 검색 결과
- API 응답
- 환경 상태 변화
작동 메커니즘
기본 구조
Thought 1: [문제를 이해하고 첫 번째 단계를 계획]
Action 1: [외부 도구 호출]
Observation 1: [도구 실행 결과]
Thought 2: [결과를 분석하고 다음 단계 결정]
Action 2: [다음 도구 호출]
Observation 2: [도구 실행 결과]
... (필요한 만큼 반복)
Thought N: [충분한 정보를 수집했으므로 답변 제시]
Action N: Finish[최종 답변]시너지 효과
-
추론이 행동을 돕는 방식
- 행동 계획 수립 및 업데이트
- 예외 처리 방법 결정
- 정보 통합 및 추론
-
행동이 추론을 돕는 방식
- 외부 정보 제공으로 환각 방지
- 추가 정보로 추론 지원
- 실제 피드백으로 계획 조정
2. 적용 가능한 작업 유형
지식 집약적 작업 (Knowledge-Intensive Tasks)
질의응답 (Question Answering)
- 작업 특성: 다단계 추론이 필요한 복잡한 질문
- 도구: Wikipedia API, 검색 엔진
- ReAct 장점:
- 실시간 정보 검색으로 환각 방지
- 단계별 정보 수집 및 통합
- 검증 가능한 답변 생성
예시 (HotpotQA)
Question: Colorado orogeny의 동쪽 구간은 어느 지역을 형성했는가?
Thought 1: Colorado orogeny에 대해 먼저 검색해야 한다.
Action 1: Search[Colorado orogeny]
Observation 1: Colorado orogeny는 고대 산맥 형성 사건...
Thought 2: 동쪽 구간을 언급하지 않았다. 다시 검색해보자.
Action 2: Lookup[eastern sector]
Observation 2: 동쪽 구간은 Ancestral Rocky Mountains 형성...
Thought 3: 이제 Ancestral Rocky Mountains가 어디인지 확인하자.
Action 3: Search[Ancestral Rocky Mountains]
Observation 3: Ancestral Rocky Mountains는 Colorado 지역...
Thought 4: 답을 찾았다.
Action 4: Finish[Ancestral Rocky Mountains]사실 검증 (Fact Verification)
- 작업 특성: 주장의 진위 판단
- 도구: Wikipedia, 뉴스 DB
- ReAct 장점:
- 체계적 증거 수집
- 다각도 검증
- 논리적 판단 근거 제시
의사결정 작업 (Decision-Making Tasks)
대화형 환경 (Interactive Environments)
- 작업 특성: 목표 달성을 위한 연속적 행동
- 환경 예시:
- ALFWorld (텍스트 기반 가상 집안 환경)
- WebShop (온라인 쇼핑 시뮬레이션)
- ReAct 장점:
- 목표 기반 계획 수립
- 환경 피드백 반영
- 오류 복구 능력
예시 (ALFWorld)
Goal: 깨끗한 사과를 찾아서 냉장고에 넣기
Thought 1: 먼저 사과를 찾아야 한다. 식탁이나 카운터를 확인해보자.
Action 1: go to dining table 1
Observation 1: 식탁 위에 사과 1개, 책 1권이 있다.
Thought 2: 사과를 찾았다. 이제 집어서 세척해야 한다.
Action 2: take apple 1 from dining table 1
Observation 2: 사과 1을 들었다.
Thought 3: 사과를 씻어야 하므로 싱크대로 가야 한다.
Action 3: go to sink 1
Observation 3: 싱크대 1에 있다.
Thought 4: 사과를 씻는다.
Action 4: clean apple 1 with sink 1
Observation 4: 사과 1을 씻었다.
Thought 5: 이제 냉장고에 넣어야 한다.
Action 5: go to fridge 1
Observation 5: 냉장고 1에 있다.
Thought 6: 냉장고를 열고 사과를 넣는다.
Action 6: open fridge 1
Observation 6: 냉장고 1을 열었다.
Thought 7: 사과를 냉장고에 넣는다.
Action 7: put apple 1 in/on fridge 1
Observation 7: 사과 1을 냉장고 1에 넣었다.
Thought 8: 작업 완료!웹 네비게이션 (Web Navigation)
- 작업 특성: 웹사이트를 탐색하여 작업 수행
- 도구: 브라우저 제어 API
- ReAct 장점:
- 전략적 탐색
- 컨텍스트 유지
- 목표 지향적 행동
주요 실험 결과
1. 지식 집약적 벤치마크
HotpotQA (다단계 질의응답)
데이터셋 특성
- 다단계 추론이 필요한 질의응답
- Wikipedia 기반 질문
- 평균 2개 이상의 정보 소스 필요
성능 결과
- ReAct (PaLM-540B): 27.4% (EM), 41.6% (F1)
- CoT (chain-of-thought): 환각 문제로 낮은 성능
- Act-only: 추론 부족으로 정보 통합 실패
주요 개선 사항
- 환각 문제 해결: 실시간 정보 검색으로 사실 확인
- 정보 통합: 여러 문서에서 정보를 체계적으로 수집
- 투명성: 각 단계의 근거가 명확히 드러남
FEVER (사실 검증)
데이터셋 특성
- 주장의 진위 판단 (Supports/Refutes/NotEnoughInfo)
- Wikipedia 기반 증거 검색
- 복잡한 추론 필요
성능 결과
- ReAct: 증거 기반 검증으로 정확도 향상
- CoT: 외부 검증 없이 추론하여 오류 발생
- Act-only: 증거 수집은 가능하나 논리적 판단 부족
2. 의사결정 벤치마크
ALFWorld (텍스트 기반 게임 환경)
데이터셋 특성
- 6가지 유형의 가정 내 작업
- 평균 50회 행동으로 목표 달성
- 환경 피드백 기반 의사결정
성능 결과
| 방법 | 성공률 |
|---|---|
| ReAct | 71% |
| Imitation Learning | 37% |
| Reinforcement Learning | 61% |
| Act-only | 34% |
개선률
- Imitation Learning 대비: +34% (절대값)
- Reinforcement Learning 대비: +10%
- Act-only 대비: +37%
주요 발견
- Few-shot (6 examples)만으로 강력한 성능
- 추론을 통한 계획 수립이 성공률 크게 향상
- 오류 복구 능력 우수
WebShop (온라인 쇼핑 시뮬레이션)
데이터셋 특성
- 실제 Amazon 제품 정보 기반
- 속성 매칭 및 가격 비교 필요
- 평균 10회 이상 상호작용
성능 결과
| 방법 | 성공률 |
|---|---|
| ReAct | 51% |
| Imitation Learning | 41% |
| Act-only | 35% |
개선률
- Imitation Learning 대비: +10% (절대값)
- Act-only 대비: +16%
주요 발견
- 복잡한 제품 검색에서 추론이 필수
- 속성 비교 및 우선순위 결정 능력
- 단 1-2개 예시만으로 효과적 학습
3. In-Context Learning 효과
Few-Shot 성능
예시 개수별 성능 (ALFWorld)
| 예시 개수 | 성공률 |
|---|---|
| 1-shot | 62% |
| 3-shot | 68% |
| 6-shot | 71% |
관찰 결과
- 매우 적은 예시로도 강력한 성능
- 3-6개 예시가 최적
- 더 많은 예시가 항상 좋은 것은 아님
Zero-Shot 가능성
- “Thought:“와 “Action:” 키워드만으로 패턴 학습
- 성능은 Few-shot보다 낮으나 작동 가능
- 적응성이 뛰어남
4. 파인튜닝 효과
소형 모델에서의 성능
PaLM-8B/62B 파인튜닝 결과
- PaLM-8B + 파인튜닝: PaLM-540B prompting 초과
- PaLM-62B + 파인튜닝: 더 큰 개선폭
- 데이터 효율성: 3,000개 샘플로 효과
시사점
- ReAct 포맷이 학습에 효과적
- 소형 모델 배포 가능성
- 비용 효율적인 대안 제시
주요 발견 및 통찰
1. 추론과 행동의 상호 보완성
추론이 행동에 미치는 영향
1. 행동 계획 수립
- 목표를 하위 작업으로 분해
- 최적 행동 순서 결정
- 대안 전략 고려
2. 오류 복구
Thought: 검색 결과가 기대와 다르다. 다른 키워드로 시도해야겠다.
Action: Search[alternative keyword]3. 정보 통합
- 여러 소스의 정보 종합
- 모순 해결
- 최종 결론 도출
행동이 추론에 미치는 영향
1. 환각 방지
- CoT의 주요 문제: 사실이 아닌 내용 생성
- ReAct 해결책: 외부 정보로 검증
- 실험 결과: 환각 비율 대폭 감소
2. 추론 근거 제공
- 실제 데이터 기반 판단
- 검증 가능한 증거
- 신뢰성 향상
3. 컨텍스트 확장
- 모델의 학습 데이터 범위를 넘어선 정보 접근
- 최신 정보 활용
- 도메인 특화 지식 활용
2. 해석 가능성과 신뢰성
투명한 의사결정 과정
장점
-
디버깅 용이성
- 각 단계의 추론 과정 확인 가능
- 오류 발생 지점 명확히 파악
- 개선 방향 도출 용이
-
신뢰성 검증
- 사용자가 추론 과정 검토 가능
- 출처 확인 가능 (Wikipedia, API 등)
- 책임 추적 가능
-
사용자 이해도
- 왜 그런 답변이 나왔는지 이해
- AI 의사결정 과정 학습
- 인간-AI 협업 향상
실제 사례
HotpotQA 오류 분석 예시
Thought 1: Apple Remote는 어느 회사 제품일까?
Action 1: Search[Apple Remote]
Observation 1: [잘못된 정보 반환]
Thought 2: 이 정보가 정확하지 않은 것 같다. 다르게 검색해보자.
Action 2: Search[Apple Remote company]
Observation 2: [정확한 정보 반환]
Thought 3: 이제 맞는 것 같다. 이 정보를 바탕으로...- 모델이 스스로 오류를 감지하고 수정
- 각 단계에서 판단 근거가 명확
- 최종 답변의 신뢰도 평가 가능
3. 범용성과 확장성
다양한 작업 적용 가능
지식 작업
- 질의응답
- 사실 검증
- 문서 분석
- 연구 조사
의사결정 작업
- 환경 탐색
- 작업 수행
- 목표 달성
- 문제 해결
다양한 도구 통합 가능
현재 실험된 도구
- Wikipedia API
- Search Engine
- 환경 인터페이스 (ALFWorld, WebShop)
확장 가능한 도구
- 데이터베이스
- 계산기
- 코드 인터프리터
- 웹 브라우저
- API 서비스
- 로봇 제어
4. 효율성
샘플 효율성
- Few-shot: 1-6개 예시로 작동
- 파인튜닝: 3,000개 샘플로 효과적
- 전이 학습: 한 도메인에서 다른 도메인으로 쉽게 전이
계산 효율성
비용 고려사항
- 더 많은 토큰 생성 (Thought 단계 추가)
- 외부 API 호출 비용
- 전체 지연시간 증가
효율성 개선 방법
- 필요한 경우에만 추론 단계 생성
- API 호출 최소화
- 캐싱 활용
- 소형 모델 파인튜닝
실무적 함의
장점
1. 즉시 적용 가능
Prompting 기반
- 모델 재학습 불필요
- 프롬프트만 수정하면 즉시 사용
- 다양한 LLM에 적용 가능 (GPT-4, Claude, PaLM 등)
간단한 구현
prompt = """
당신은 질문에 답하기 위해 추론하고 행동하는 AI입니다.
다음 형식을 따르세요:
Thought: [현재 상황 분석 및 다음 단계 계획]
Action: [도구 호출]
Observation: [도구 실행 결과]
... (필요한 만큼 반복)
Thought: [최종 답변 제시]
Action: Finish[답변]
Question: {question}
"""2. 환각 문제 해결
CoT의 근본적 한계
- 모델이 알고 있다고 “생각하는” 지식에 의존
- 잘못된 정보나 오래된 정보 생성 가능
- 검증 방법 없음
ReAct의 해결책
- 외부 신뢰 가능한 소스에서 정보 검색
- 실시간 정보 활용
- 출처 추적 가능
3. 유연성과 확장성
도구 추가 용이
# 새로운 도구 정의
tools = {
"Search": wikipedia_search,
"Lookup": wikipedia_lookup,
"Calculator": calculator,
"CodeInterpreter": code_interpreter,
# 필요한 도구를 계속 추가 가능
}도메인 적응
- 도메인별 도구만 변경하면 됨
- 프롬프트 템플릿 재사용 가능
- 빠른 프로토타이핑 가능
4. 투명성과 제어 가능성
의사결정 과정 가시화
- 각 단계의 추론 확인
- 도구 호출 이력 추적
- 오류 진단 용이
인간 개입 가능
- 특정 단계에서 개입 가능
- 추론 방향 조정 가능
- 안전장치 구현 가능
적용 분야
고객 지원 (Customer Support)
활용 방식
Thought: 고객이 주문 상태를 문의했다. 주문 번호로 조회해야겠다.
Action: CheckOrderStatus[ORDER123]
Observation: 주문이 배송 중이며 내일 도착 예정
Thought: 배송 추적 정보도 제공하면 좋겠다.
Action: GetTrackingInfo[ORDER123]
Observation: 추적번호: TRACK456, 현재 위치: 고객 지역 물류센터
Thought: 충분한 정보를 수집했다. 친절하게 답변하자.
Action: Finish[주문하신 제품은 현재 배송 중이며...]이점
- 실시간 정보 조회
- 정확한 답변 제공
- 추가 정보 자동 제공
- 고객 만족도 향상
연구 조사 (Research Assistant)
활용 방식
- 학술 논문 검색 및 요약
- 여러 소스의 정보 통합
- 주장의 근거 찾기
- 관련 자료 추천
이점
- 체계적 조사 과정
- 출처 기반 정보 제공
- 시간 절약
- 포괄적 조사
데이터 분석 (Data Analysis)
활용 방식
Thought: 매출 데이터를 분석해야 한다. 먼저 데이터를 조회하자.
Action: QueryDatabase[SELECT * FROM sales WHERE date >= '2023-01']
Observation: [데이터 반환]
Thought: 월별 추세를 계산해야겠다.
Action: Calculator[monthly_trend_analysis]
Observation: [분석 결과]
Thought: 시각화하여 보고서를 만들자.
Action: CreateChart[line_chart, monthly_sales]
Observation: [차트 생성 완료]
Thought: 인사이트를 요약하자.
Action: Finish[2023년 매출은 분기별로 20% 증가...]이점
- 데이터 조회 자동화
- 다단계 분석 수행
- 해석과 함께 결과 제시
- 재현 가능한 분석 과정
교육 (Education)
활용 방식
- 단계별 문제 풀이 설명
- 추가 자료 검색 및 제공
- 학생 질문에 맞춤형 답변
- 개념 간 연결 설명
이점
- 소크라테스식 교수법
- 학습자 수준에 맞춘 설명
- 실시간 정보 업데이트
- 학습 과정 추적 가능
소프트웨어 개발 (Software Development)
활용 방식
Thought: 버그 리포트를 분석해야 한다. 먼저 로그를 확인하자.
Action: CheckLogs[error_logs, last_24h]
Observation: [에러 로그 반환]
Thought: 관련 코드를 찾아보자.
Action: SearchCode[error_function_name]
Observation: [코드 위치 반환]
Thought: 유사한 이슈가 있었는지 확인하자.
Action: SearchIssues[similar_error]
Observation: [관련 이슈 #123 발견]
Thought: 이전 해결 방법을 참고하여 수정 방안을 제시하자.
Action: Finish[이 버그는 이전 이슈 #123과 유사하며...]이점
- 체계적 디버깅
- 컨텍스트 기반 제안
- 과거 사례 활용
- 문서 자동 생성
의료 (Healthcare)
활용 방식
- 증상 기반 정보 검색
- 의학 문헌 조회
- 약물 상호작용 확인
- 진단 지원 (의사 보조)
이점
- 최신 의학 정보 접근
- 증거 기반 제안
- 다각도 검토
- 안전성 확인
주의사항
- 최종 판단은 반드시 전문가가 수행
- 법적 책임 고려
- 환자 안전 최우선
한계점 및 도전 과제
1. 기술적 한계
추론 체인의 품질
문제점
- 항상 올바른 추론을 생성하지 않음
- 불필요한 단계 생성 가능
- 무한 루프 위험
예시
Thought: A를 검색해야겠다.
Action: Search[A]
Observation: [결과]
Thought: 결과가 불충분하다. A를 다시 검색하자.
Action: Search[A]
Observation: [동일한 결과]
Thought: 결과가 불충분하다. A를 다시 검색하자.
[무한 반복...]완화 방법
- 최대 단계 수 제한
- 반복 탐지 메커니즘
- 대안 전략 프롬프트 포함
도구 사용 오류
문제점
- 잘못된 도구 선택
- 부적절한 매개변수
- 도구 출력 오해석
완화 방법
- 명확한 도구 설명 제공
- 사용 예시 포함
- 오류 처리 메커니즘
컨텍스트 길이 제약
문제점
- 긴 추론 체인은 많은 토큰 소비
- 컨텍스트 윈도우 초과 가능
- 초기 정보 손실 위험
완화 방법
- 중요 정보만 유지
- 메모리 메커니즘 도입
- 요약 기능 활용
2. 비용 및 효율성
추론 비용
비용 요소
- 토큰 비용: Thought 단계로 출력 토큰 증가
- API 호출 비용: 외부 도구 사용 비용
- 지연시간: 여러 단계 실행으로 응답 시간 증가
비용 분석 (예시)
- 표준 프롬프팅: 100 토큰 출력
- CoT: 200 토큰 출력 (2배)
- ReAct: 300-500 토큰 출력 (3-5배) + API 비용
최적화 전략
- 선택적 사용: 복잡한 작업에만 ReAct 적용
- 조기 종료: 충분한 정보 수집 시 즉시 종료
- 캐싱: 반복 검색 결과 캐시
- 소형 모델: 파인튜닝된 작은 모델 사용
3. 실무적 고려사항
도구 의존성
문제점
- 도구의 품질이 성능에 직접 영향
- 도구 장애 시 시스템 전체 영향
- 도구 API 변경 시 업데이트 필요
대응 방안
- 백업 도구 준비
- 도구 헬스 체크
- API 버전 관리
- 대체 전략 구현
프롬프트 엔지니어링
필요 작업
- 도메인별 프롬프트 최적화
- 예시 작성 및 유지보수
- 오류 케이스 처리
- 지속적인 개선
도전 과제
- 전문 지식 필요
- 시행착오 과정 필요
- 도메인 변경 시 재작업
- 품질 관리 부담
안전성 및 신뢰성
잠재적 위험
-
악의적 도구 사용
- 유해한 검색 수행
- 민감한 데이터 접근
- 시스템 조작
-
정보 오염
- 잘못된 정보 소스
- 편향된 데이터
- 오래된 정보
-
책임 문제
- 잘못된 답변의 책임 소재
- 법적 리스크
- 윤리적 고려사항
안전 장치
# 도구 사용 제한
allowed_tools = ["Search", "Lookup"] # 안전한 도구만 허용
# 도구 호출 검증
def validate_action(action):
if action.tool not in allowed_tools:
raise SecurityError("Unauthorized tool")
if contains_sensitive_query(action.query):
raise SecurityError("Sensitive query detected")
return True
# 출력 필터링
def filter_output(output):
if contains_harmful_content(output):
return "[Content filtered]"
return output4. 평가의 어려움
평가 지표
기존 지표의 한계
- 정확도만으로는 불충분
- 추론 과정의 품질 측정 어려움
- 효율성과 효과성의 트레이드오프
종합적 평가 필요
- 작업 성공률: 최종 목표 달성 여부
- 효율성: 필요한 단계 수, 비용
- 추론 품질: 논리적 일관성, 관련성
- 신뢰성: 재현 가능성, 안정성
- 해석 가능성: 이해하기 쉬운 정도
후속 연구 및 발전
1. ReAct 변형 및 개선
Reflexion (2023)
핵심 아이디어
- ReAct + 자기 반성(Self-Reflection)
- 실패한 시도를 분석하고 개선
- 에피소드 메모리 활용
메커니즘
[첫 번째 시도]
Thought → Action → Observation (실패)
[반성]
Reflection: 실패 원인 분석, 개선 방안 도출
[두 번째 시도]
Thought (반성 반영) → Action → Observation (성공)성과
- 복잡한 작업에서 성공률 추가 향상
- 시행착오 학습 능력
Toolformer (2023)
차이점
- ReAct: Prompting 기반
- Toolformer: 모델 자체에 도구 사용 능력 학습
방법
- 대량의 도구 사용 예시로 학습
- 언제, 어떤 도구를 사용할지 모델이 자동 결정
2. 멀티모달 확장
시각-언어 ReAct
확장 내용
- 이미지 분석 도구 통합
- 시각적 추론 단계 포함
예시
Thought: 이 이미지에서 물체를 식별해야 한다.
Action: ObjectDetection[image]
Observation: 개, 고양이, 나무 감지됨
Thought: 개의 품종을 확인하자.
Action: ImageClassification[dog_region]
Observation: 골든 리트리버로 분류됨로봇 제어
적용 분야
- 가정용 로봇
- 산업용 로봇
- 자율주행
예시
Thought: 물건을 집어야 한다. 먼저 위치를 확인하자.
Action: CameraCapture[]
Observation: [이미지]
Thought: 물건이 왼쪽에 있다. 로봇 팔을 이동시키자.
Action: MoveArm[x=50, y=20, z=10]
Observation: 팔 이동 완료
Thought: 이제 그리퍼를 닫아서 잡자.
Action: CloseGripper[]
Observation: 물건 파지 성공3. 학습 방법 개선
강화학습과의 통합
접근법
- ReAct 궤적을 보상 신호로 활용
- 성공한 추론 패턴 강화
- 실패 패턴 억제
이점
- 데이터 효율적 학습
- 지속적 개선
- 도메인 적응 가능
Curriculum Learning
방법
- 쉬운 작업부터 어려운 작업으로 점진적 학습
- ReAct 패턴을 단계별로 학습
효과
- 학습 안정성 향상
- 수렴 속도 개선
- 일반화 능력 강화
4. 확장성 개선
분산 실행
병렬 도구 호출
Thought: 여러 소스에서 동시에 정보를 수집해야겠다.
Action: Parallel[
Search[source1],
Search[source2],
Search[source3]
]
Observation: [모든 결과를 동시에 받음]이점
- 실행 시간 단축
- 효율성 향상
- 더 많은 정보 처리
계층적 ReAct
개념
- 상위 레벨: 전략적 계획
- 하위 레벨: 세부 실행
예시
[상위 레벨]
Thought: 이 복잡한 질문은 3개의 하위 질문으로 나눌 수 있다.
Action: CreateSubtasks[q1, q2, q3]
[하위 레벨 - 각 서브태스크별로 독립적 ReAct 실행]
Subtask 1: Thought → Action → Observation → ...
Subtask 2: Thought → Action → Observation → ...
Subtask 3: Thought → Action → Observation → ...
[상위 레벨]
Thought: 모든 서브태스크 결과를 통합하자.
Action: Finish[통합된 답변]5. 새로운 적용 분야
과학 연구 자동화
- 가설 생성
- 실험 설계
- 데이터 분석
- 논문 작성
법률 분석
- 판례 검색
- 법률 해석
- 계약서 검토
- 규정 준수 확인
창의적 작업
- 콘텐츠 생성 (블로그, 기사)
- 코드 작성 및 디버깅
- 디자인 제안
- 전략 수립
관련 개념
- CoT - 사고 사슬 프롬프팅으로 추론 능력 향상 - ReAct의 추론 부분 기반
- ACE - 진화하는 컨텍스트를 통한 자가 개선 - 컨텍스트 엔지니어링
- 초기 경험을 통한 에이전트 학습 - 에이전트 학습 방법
- 에이전트 도구 사용
- ReAct 패턴
- Toolformer: 도구 사용 학습 모델
- Reflexion: 자기 반성 능력 추가
- WebGPT: 웹 브라우징 기반 QA
참고 자료
- 최신 AI 연구 논문
- 에이전트 개발을 위해 반드시 읽어야 할 핵심 논문
- 학습 자료 모음
- 논문: https://arxiv.org/abs/2210.03629
- 프로젝트 사이트: https://react-lm.github.io/
- 코드: https://github.com/ysymyth/ReAct
실전 가이드
ReAct 구현 체크리스트
1. 프롬프트 설계
기본 구조 정의
system_prompt = """
당신은 추론과 행동을 통해 문제를 해결하는 AI 어시스턴트입니다.
다음 형식을 반드시 따르세요:
Thought: [현재 상황을 분석하고 다음 단계를 계획]
Action: [도구이름][매개변수]
Observation: [도구 실행 결과 - 자동으로 제공됨]
... (필요한 만큼 반복)
Thought: [충분한 정보를 수집했으므로 최종 답변 제시]
Action: Finish[최종 답변]
사용 가능한 도구:
- Search[query]: 주어진 쿼리로 Wikipedia 검색
- Lookup[keyword]: 마지막 검색 결과에서 키워드 찾기
- Finish[answer]: 최종 답변 제시 및 종료
주의사항:
- 각 단계에서 신중하게 생각하세요
- 확실하지 않으면 추가 검색을 수행하세요
- 여러 소스의 정보를 확인하여 검증하세요
"""Few-shot 예시 작성
examples = """
Question: Colorado orogeny의 동쪽 구간은 어느 지역을 형성했는가?
Thought 1: Colorado orogeny에 대해 검색해야겠다.
Action 1: Search[Colorado orogeny]
Observation 1: Colorado orogeny는 콜로라도와 주변 지역의 산맥 형성 사건이다...
Thought 2: 동쪽 구간에 대한 언급이 없다. "eastern sector"를 찾아보자.
Action 2: Lookup[eastern sector]
Observation 2: (Result 1/1) 동쪽 구간은 Ancestral Rocky Mountains를 형성했다.
Thought 3: Ancestral Rocky Mountains가 답인 것 같다. 확인을 위해 검색해보자.
Action 3: Search[Ancestral Rocky Mountains]
Observation 3: Ancestral Rocky Mountains는 고대 산맥으로...
Thought 4: 확인했다. 답은 Ancestral Rocky Mountains이다.
Action 4: Finish[Ancestral Rocky Mountains]
---
Question: {user_question}
"""2. 도구 구현
도구 인터페이스 정의
from typing import Dict, Any, Callable
class Tool:
def __init__(self, name: str, func: Callable, description: str):
self.name = name
self.func = func
self.description = description
def execute(self, *args, **kwargs) -> str:
try:
result = self.func(*args, **kwargs)
return str(result)
except Exception as e:
return f"Error: {str(e)}"
# 도구 정의
def wikipedia_search(query: str) -> str:
"""Wikipedia에서 검색"""
# 실제 구현
pass
def wikipedia_lookup(keyword: str) -> str:
"""마지막 검색 결과에서 키워드 찾기"""
# 실제 구현
pass
tools = {
"Search": Tool("Search", wikipedia_search, "Wikipedia 검색"),
"Lookup": Tool("Lookup", wikipedia_lookup, "검색 결과에서 키워드 찾기"),
}3. ReAct 에이전트 구현
기본 에이전트 클래스
import re
from typing import List, Tuple
class ReActAgent:
def __init__(self, llm, tools: Dict[str, Tool], max_steps: int = 10):
self.llm = llm
self.tools = tools
self.max_steps = max_steps
self.history: List[str] = []
def parse_action(self, text: str) -> Tuple[str, str]:
"""
텍스트에서 Action을 파싱
예: "Action 1: Search[Colorado orogeny]"
-> ("Search", "Colorado orogeny")
"""
pattern = r"Action \d+: (\w+)\[(.*?)\]"
match = re.search(pattern, text)
if match:
tool_name = match.group(1)
tool_input = match.group(2)
return tool_name, tool_input
return None, None
def run(self, question: str) -> str:
"""ReAct 루프 실행"""
prompt = f"Question: {question}\n\n"
self.history = [prompt]
for step in range(1, self.max_steps + 1):
# LLM으로 다음 단계 생성
current_prompt = "".join(self.history)
response = self.llm.generate(current_prompt)
# 히스토리에 추가
self.history.append(response)
# Finish 액션 확인
if "Finish[" in response:
# 최종 답변 추출
answer = re.search(r"Finish\[(.*?)\]", response).group(1)
return answer
# Action 파싱
tool_name, tool_input = self.parse_action(response)
if tool_name is None:
# 파싱 실패 - 재시도 프롬프트
self.history.append(
"\n[System: Action 형식이 잘못되었습니다. "
"'Action N: ToolName[input]' 형식으로 작성해주세요.]\n"
)
continue
# 도구 실행
if tool_name not in self.tools:
observation = f"Error: Unknown tool '{tool_name}'"
else:
observation = self.tools[tool_name].execute(tool_input)
# Observation 추가
self.history.append(f"\nObservation {step}: {observation}\n\n")
return "Error: Maximum steps reached without answer"
# 사용 예시
agent = ReActAgent(llm=my_llm, tools=tools)
answer = agent.run("Colorado orogeny의 동쪽 구간은 어느 지역을 형성했는가?")
print(answer)4. 개선 기법
루프 방지
class ReActAgent:
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.action_history: List[Tuple[str, str]] = []
def is_repetitive(self, tool_name: str, tool_input: str) -> bool:
"""동일한 액션이 최근에 반복되었는지 확인"""
recent_actions = self.action_history[-3:] # 최근 3개
action = (tool_name, tool_input)
return recent_actions.count(action) >= 2
def run(self, question: str) -> str:
# ... 기존 코드 ...
# 도구 실행 전
if self.is_repetitive(tool_name, tool_input):
self.history.append(
"\n[System: 동일한 액션이 반복되고 있습니다. "
"다른 접근 방법을 시도해보세요.]\n"
)
continue
# 액션 히스토리에 추가
self.action_history.append((tool_name, tool_input))
# ... 도구 실행 ...오류 복구
class ReActAgent:
def run(self, question: str) -> str:
retry_count = 0
max_retries = 3
# ... 기존 코드 ...
# 도구 실행
try:
if tool_name not in self.tools:
observation = f"Error: Unknown tool '{tool_name}'"
else:
observation = self.tools[tool_name].execute(tool_input)
retry_count = 0 # 성공 시 리셋
except Exception as e:
retry_count += 1
if retry_count >= max_retries:
observation = f"Error: Tool failed after {max_retries} attempts: {str(e)}"
else:
observation = f"Error: {str(e)}. Please try again with different input."5. 프로덕션 체크리스트
배포 전 확인사항
- 다양한 테스트 케이스로 검증
- 무한 루프 방지 메커니즘 구현
- 도구 오류 처리 구현
- 최대 단계 수 적절히 설정
- 비용 예산 설정 (API 호출 제한)
- 로깅 및 모니터링 구현
- 안전 필터 구현 (유해 쿼리 차단)
- 성능 벤치마크 수행
- 문서화 완료
운영 중 모니터링
- 평균 단계 수 추적
- 성공률 측정
- 비용 추적 (토큰, API 호출)
- 지연시간 모니터링
- 오류 패턴 분석
- 사용자 피드백 수집
- 프롬프트 효과성 평가
지속적 개선
- A/B 테스트로 프롬프트 최적화
- 도구 성능 개선
- Few-shot 예시 업데이트
- 오류 케이스 분석 및 대응
- 새로운 도구 추가
- 비용 최적화
핵심 요약
ReAct의 핵심 가치
-
추론 + 행동의 시너지
- 단순 합 이상의 효과
- 상호 보완적 관계
- 환각 문제 해결
-
투명성과 신뢰성
- 해석 가능한 의사결정
- 검증 가능한 출처
- 디버깅 용이
-
실용성
- 즉시 적용 가능 (Prompting)
- 다양한 도메인 적응
- 비용 효율적 (파인튜닝 불요)
-
확장성
- 새로운 도구 추가 용이
- 멀티모달 확장 가능
- 계층적 구조 지원
적용 시 주요 고려사항
언제 ReAct를 사용해야 하는가?
✅ 사용 권장
- 외부 정보가 필요한 작업
- 다단계 추론이 필요한 작업
- 투명성이 중요한 작업
- 도구 사용이 필요한 작업
❌ 사용 비권장
- 단순한 작업 (오버헤드)
- 실시간성이 매우 중요한 작업 (지연시간)
- 비용이 매우 민감한 작업
- 도구가 없거나 신뢰할 수 없는 환경
성공적인 구현을 위한 핵심
-
좋은 프롬프트 작성
- 명확한 지시사항
- 적절한 few-shot 예시
- 도구 설명 포함
-
신뢰할 수 있는 도구
- 안정적인 API
- 정확한 결과
- 오류 처리
-
적절한 제약 조건
- 최대 단계 수
- 타임아웃
- 비용 제한
-
지속적인 모니터링과 개선
- 성능 추적
- 오류 분석
- 프롬프트 최적화