기본 정보
- 제목: Lost in the Middle: How Language Models Use Long Contexts
- 저자: Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang
- 소속: Stanford University, Meta AI Research
- 발표일: 2023년 7월 6일 (arXiv), 2023년 (TACL)
- arXiv: https://arxiv.org/abs/2307.03172
- 분야: Computation and Language, Information Retrieval
- 학회: TACL 2023 (Transactions of the Association for Computational Linguistics)
연구 개요
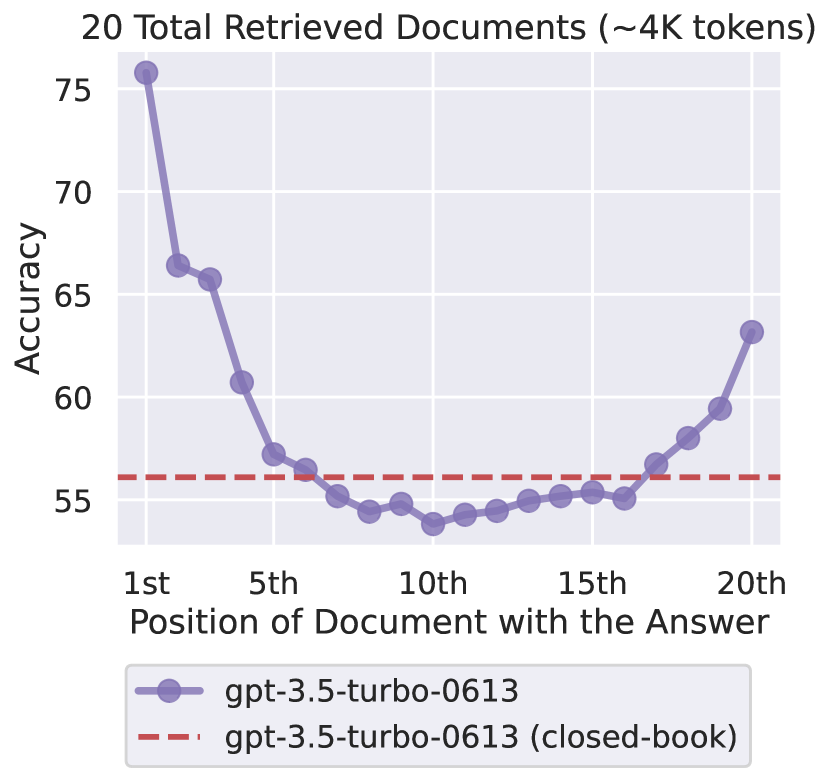
이 논문은 대규모 언어 모델이 긴 입력 컨텍스트를 실제로 얼마나 효과적으로 활용하는지를 실증적으로 분석합니다. 여러 다중 문서 질의응답 및 키-값 검색 작업을 통해, 연구진은 중요한 발견을 했습니다: 관련 정보가 입력의 시작 부분이나 끝 부분에 있을 때 성능이 가장 높고, 중간에 있을 때는 성능이 크게 저하됩니다. 이 현상은 긴 컨텍스트를 처리하도록 설계된 모델에서도 나타나며, 현대 언어 모델이 입력 컨텍스트 전체에 걸쳐 정보를 견고하게 활용하는 데 어려움을 겪고 있음을 보여줍니다.
핵심 개념
1. 위치 편향 (Positional Bias)
기본 현상
정의
- 언어 모델의 성능이 정보의 내용보다 위치에 따라 크게 달라지는 현상
- 동일한 정보라도 컨텍스트 내 위치에 따라 활용도가 현저히 다름
U자형 성능 곡선 (U-Shaped Performance Curve)
성능 (정확도)
↑
높음│ ● ●
│ ● ●
│ ● ●
중간│ ● ●
│ ● ●
│ ● ●
낮음│ ●●●●
│
└────────────────────────────────→
시작 ← 중간 → 끝
문서 위치
특징
-
시작 부분 (Beginning): 높은 성능
- 모델이 초기 정보를 효과적으로 활용
- 첫 문서나 첫 단락에서 정보를 잘 찾음
-
중간 부분 (Middle): 급격한 성능 저하
- 20-40% 정확도 감소
- 정보가 “묻혀버림” (lost)
- 가장 큰 문제 영역
-
끝 부분 (End): 성능 회복
- 시작 부분에 근접한 성능
- 최근 정보에 대한 높은 가중치
- Recency bias 효과
왜 이런 현상이 발생하는가?
가설적 원인
-
주의 메커니즘 (Attention Mechanism)
- Transformer의 주의 패턴이 양 끝에 집중
- 중간 부분에 대한 주의 가중치 감소
- 위치 인코딩의 영향
-
학습 데이터 편향
- 학습 시 중요한 정보가 시작이나 끝에 위치하는 경우가 많음
- 문서 구조의 일반적 패턴 (서론-본론-결론)
- 학습된 패턴이 평가 시에도 나타남
-
정보 처리 용량
- 긴 컨텍스트 처리 시 중간 정보가 “희석”됨
- 표현 능력의 한계
- 계산 자원의 분산
-
인간의 독해 패턴 모방
- 인간도 긴 문서에서 시작과 끝을 더 잘 기억
- Primacy effect (초두 효과)
- Recency effect (최신 효과)
2. 평가 작업 (Evaluation Tasks)
다중 문서 질의응답 (Multi-Document Question Answering)
작업 설명
- 여러 문서 중 하나 이상에 답변이 포함됨
- 모델은 관련 정보를 찾아 답변 생성
- 문서의 순서와 위치가 변수
실험 설정
# 예시 구조
context = f"""
문서 1: [관련 없는 내용]
문서 2: [관련 없는 내용]
문서 3: [답변이 있는 내용] ← 위치를 변경하며 실험
문서 4: [관련 없는 내용]
...
문서 N: [관련 없는 내용]
질문: {question}
"""성능 측정
- 관련 문서를 다양한 위치에 배치
- 각 위치별 정답률 측정
- 위치에 따른 성능 변화 분석
주요 발견
| 문서 위치 | 정확도 (예시) | 성능 변화 |
|---|---|---|
| 1번째 (시작) | 85% | 기준 |
| 5번째 (중간 초반) | 70% | -15% |
| 10번째 (정중앙) | 55% | -30% |
| 15번째 (중간 후반) | 68% | -17% |
| 20번째 (끝) | 82% | -3% |
키-값 검색 (Key-Value Retrieval)
작업 설명
- 구조화된 정보 검색 작업
- 키를 제시하고 대응하는 값을 찾기
- 정보의 정확한 위치 파악 필요
예시
{
"PassportNumber": "AB123456",
"BirthDate": "1990-01-01",
"Address": "123 Main St",
...
"TargetKey": "TargetValue", ← 이 위치를 변경
...
"PhoneNumber": "555-1234",
"Email": "[email protected]"
}
질문: TargetKey의 값은?
정답: TargetValue특징
- 답이 명확함 (정확 매칭)
- 위치 효과를 순수하게 측정 가능
- 추론이 거의 필요 없음
결과
- 다중 문서 QA와 유사한 U자형 패턴
- 중간 위치의 키-값 쌍 검색 실패율 높음
- 단순한 검색 작업에서도 위치 편향 존재
3. 실험 대상 모델
평가된 모델들
오픈소스 모델
-
MPT-30B-Instruct
- MosaicML의 30B 파라미터 모델
- 긴 컨텍스트 지원 (8K 토큰)
-
LongChat-13B
- Vicuna 기반 확장 모델
- 16K 토큰 컨텍스트 윈도우
상용 모델 (API)
-
GPT-3.5-Turbo
- OpenAI의 중형 모델
- 4K/16K 토큰 버전
-
Claude-1.3
- Anthropic의 모델
- 100K 토큰 컨텍스트 윈도우
공통 발견
- 모든 모델에서 U자형 패턴 관찰
- 컨텍스트 윈도우 크기와 무관
- 모델 크기나 아키텍처와 무관
- 보편적 현상임을 시사
모델별 차이점
상대적 성능
| 모델 | 중간 위치 성능 저하 | 강점 |
|---|---|---|
| GPT-3.5-Turbo | 보통 | 전반적으로 균형잡힌 성능 |
| Claude-1.3 | 작음 | 매우 긴 컨텍스트 처리 |
| MPT-30B | 큼 | 오픈소스, 커스터마이징 가능 |
| LongChat-13B | 큼 | 경량, 빠른 추론 |
관찰 사항
- Claude-1.3: 100K 토큰 지원에도 불구하고 위치 편향 존재
- 긴 컨텍스트 “지원”과 “활용”은 다른 문제
- 기술적 능력 ≠ 실제 활용 능력
주요 실험 결과
1. NaturalQuestions 벤치마크
실험 설정
데이터셋
- Google의 실제 검색 질의 기반
- 자연스러운 질문과 답변
- Wikipedia 문서에서 답변 추출
방법론
# 실험 프로토콜
def evaluate_position(question, answer_doc, distractor_docs):
"""
answer_doc: 정답이 포함된 문서
distractor_docs: 관련 없는 방해 문서들 (10-20개)
"""
for position in range(len(distractor_docs) + 1):
# answer_doc를 position 위치에 삽입
docs = distractor_docs[:position] + [answer_doc] + distractor_docs[position:]
# 모델 평가
response = model.generate(docs, question)
accuracy[position] = evaluate(response, answer)
return accuracy결과
GPT-3.5-Turbo (16K)
| 문서 위치 | 정확도 | 기준 대비 |
|---|---|---|
| 1 (시작) | 62.3% | 기준 |
| 3 | 58.1% | -4.2% |
| 5 | 51.2% | -11.1% |
| 10 (중간) | 42.8% | -19.5% |
| 15 | 49.3% | -13.0% |
| 20 (끝) | 59.7% | -2.6% |
Claude-1.3 (100K)
- 더 완만한 곡선이지만 여전히 U자형
- 중간 위치에서 약 10-15% 성능 저하
- 긴 컨텍스트에서도 문제 지속
핵심 발견
-
절대적 위치보다 상대적 위치가 중요
- 10개 문서 중 5번째 vs 20개 문서 중 10번째
- 상대적 중앙 위치에서 유사한 성능 저하
-
문서 개수의 영향
- 더 많은 방해 문서 → 더 큰 성능 저하
- 10개 문서: 중간에서 -15%
- 20개 문서: 중간에서 -25%
2. TriviaQA 벤치마크
실험 설정
데이터셋 특성
- 트리비아 질문 (일반 상식)
- 웹 문서 기반 답변
- 다양한 난이도
결과 패턴
전체 모델 평균
성능 변화 (시작 위치 기준)
Position 1: 100% (기준)
Position 5: 82% (-18%)
Position 10: 65% (-35%)
Position 15: 79% (-21%)
Position 20: 94% (-6%)
관찰 사항
- NaturalQuestions보다 더 뚜렷한 U자형
- 상식 질문에서도 위치 편향 명확
- 쉬운 질문도 위치에 영향 받음
3. 키-값 검색 (Synthetic Task)
실험 설계
합성 데이터
{
"key_0": "value_0",
"key_1": "value_1",
...
"key_50": "value_50",
...
"key_99": "value_99"
}
Query: "What is the value of key_50?"장점
- 완벽한 통제
- 정확한 위치 측정
- 노이즈 최소화
결과
정확 매칭 정확도
| 키 위치 | GPT-3.5 | Claude-1.3 | MPT-30B |
|---|---|---|---|
| 0-10 (시작) | 98% | 99% | 95% |
| 20-30 | 87% | 92% | 78% |
| 40-60 (중간) | 62% | 75% | 51% |
| 70-80 | 85% | 90% | 73% |
| 90-99 (끝) | 96% | 98% | 92% |
핵심 통찰
-
단순 검색도 위치 영향
- 복잡한 추론 불필요한 작업
- 위치 편향이 근본적 문제임을 시사
-
모델별 차이
- Claude-1.3: 가장 견고
- MPT-30B: 가장 취약
- 모델 설계의 중요성
4. 컨텍스트 길이의 영향
실험 변수
문서 개수 증가
- 5개, 10개, 20개, 30개 문서
- 각 설정에서 위치별 성능 측정
결과
성능 저하 폭
| 문서 개수 | 중간 위치 성능 저하 | 최저 정확도 |
|---|---|---|
| 5개 | -12% | 78% |
| 10개 | -18% | 69% |
| 20개 | -28% | 55% |
| 30개 | -35% | 48% |
발견 사항
-
선형적 악화
- 문서가 많아질수록 중간 위치 성능 급격히 하락
- 단순히 “긴 컨텍스트 지원”만으로는 불충분
-
상대적 위치의 일관성
- 절대 위치보다 상대 위치(중앙)에서 최저 성능
- 정규화된 위치로 분석 필요
5. 프롬프트 전략의 영향
실험 방법
다양한 프롬프팅 기법 테스트
-
기본 프롬프트
다음 문서들을 읽고 질문에 답하세요. [문서들] 질문: {question} -
명시적 지시
모든 문서를 주의 깊게 읽고, 어느 위치에 있든 관련 정보를 찾아 답하세요. [문서들] 질문: {question} -
단계별 추론
1단계: 각 문서를 검토하세요 2단계: 관련 정보를 찾으세요 3단계: 답변을 작성하세요 [문서들] 질문: {question}
결과
프롬프트 개선 효과
| 방법 | 중간 위치 성능 개선 | 전체 성능 변화 |
|---|---|---|
| 기본 | 기준 (42.8%) | 기준 |
| 명시적 지시 | +2.3% (45.1%) | +1.1% |
| 단계별 추론 | +4.7% (47.5%) | +2.8% |
관찰
- 프롬프트 개선으로 부분적 완화 가능
- 근본적 해결은 아님
- 여전히 U자형 패턴 존재
- 추가 토큰 비용 발생
주요 발견 및 통찰
1. 컨텍스트 윈도우 크기 ≠ 실제 활용 능력
기술적 능력 vs 실제 성능
기술적 능력
- Claude-1.3: 100K 토큰 지원
- GPT-4: 32K 토큰 지원
- 긴 입력을 “받을 수 있음”
실제 성능
- 중간 부분 정보 활용 실패
- 위치에 따라 20-40% 성능 차이
- “지원”과 “활용”의 괴리
시사점
“Having a long context window is necessary but not sufficient for effectively using long contexts”
- 단순히 긴 컨텍스트를 “받을 수 있음” ≠ “잘 사용함”
- 평가 기준 재고 필요
- 실제 활용 능력 측정 중요
2. RAG 시스템에 대한 함의
문서 순서의 중요성
일반적인 RAG 파이프라인
# 전형적인 RAG 구현
def rag_pipeline(query):
# 1. 문서 검색
docs = retrieve_documents(query, top_k=10)
# 2. 유사도 순으로 정렬
docs = sorted(docs, key=lambda x: x.similarity, reverse=True)
# 3. 컨텍스트 구성 (문제!)
context = "\n\n".join([doc.text for doc in docs])
# 4. LLM 호출
response = llm.generate(context + "\n\n" + query)
return response문제점
- 유사도 순 정렬이 최적이 아닐 수 있음
- 중간에 있는 관련 문서가 무시될 수 있음
- 순서 최적화 필요
개선 전략
1. 중요 문서를 양 끝에 배치
def optimized_rag_pipeline(query):
docs = retrieve_documents(query, top_k=10)
# 유사도로 정렬
sorted_docs = sorted(docs, key=lambda x: x.similarity, reverse=True)
# 재배치: 중요한 문서를 시작과 끝에
reordered = []
for i, doc in enumerate(sorted_docs):
if i % 2 == 0:
reordered.insert(0, doc) # 시작에 추가
else:
reordered.append(doc) # 끝에 추가
context = "\n\n".join([doc.text for doc in reordered])
response = llm.generate(context + "\n\n" + query)
return response2. 검색 문서 수 제한
# 더 적은 문서로 더 나은 결과
def reduced_rag_pipeline(query):
# 10개 대신 3-5개만 사용
docs = retrieve_documents(query, top_k=5)
# 가장 관련성 높은 문서만 사용하여 위치 편향 최소화
context = "\n\n".join([doc.text for doc in docs[:3]])
response = llm.generate(context + "\n\n" + query)
return response3. 다중 쿼리 전략
def multi_query_rag_pipeline(query):
"""각 문서를 독립적으로 처리"""
docs = retrieve_documents(query, top_k=10)
results = []
for doc in docs[:5]: # 상위 5개만
# 각 문서를 개별적으로 LLM에 전달 (위치 편향 제거)
context = doc.text
result = llm.generate(context + "\n\n" + query)
results.append(result)
# 결과 통합
final_answer = aggregate_results(results)
return final_answer4. 계층적 접근
def hierarchical_rag_pipeline(query):
"""긴 컨텍스트를 청크로 나누어 처리"""
docs = retrieve_documents(query, top_k=20)
# 1단계: 청크별 처리 (각 청크는 짧음)
chunks = [docs[i:i+3] for i in range(0, len(docs), 3)]
summaries = []
for chunk in chunks:
context = "\n\n".join([doc.text for doc in chunk])
summary = llm.generate(f"Extract relevant info:\n{context}\n\nQuery: {query}")
summaries.append(summary)
# 2단계: 요약을 모아서 최종 답변
final_context = "\n\n".join(summaries)
final_answer = llm.generate(final_context + "\n\n" + query)
return final_answer3. 평가 방법론의 재고
기존 벤치마크의 한계
문제점
-
위치 편향 고려 안 함
- 대부분의 벤치마크가 고정된 문서 순서
- 우연히 좋은 위치에 정답이 있을 수 있음
- 실제 능력을 과대평가
-
짧은 컨텍스트 중심
- 전통적 QA 벤치마크는 짧은 passage
- 긴 컨텍스트 처리 능력 평가 부족
-
단일 정답 패러다임
- 실제 환경: 여러 문서에서 정보 통합 필요
- 벤치마크: 단일 문서에서 답 찾기
개선된 평가 방법
위치 무작위화 (Position Randomization)
def robust_evaluation(model, dataset):
"""위치를 무작위화하여 평가"""
results = []
for sample in dataset:
question = sample.question
answer_doc = sample.answer_document
distractor_docs = sample.distractors
# 여러 번 위치를 바꿔가며 평가
position_results = []
for trial in range(10):
# 무작위 위치에 answer_doc 삽입
position = random.randint(0, len(distractor_docs))
docs = distractor_docs[:position] + [answer_doc] + distractor_docs[position:]
response = model.generate(docs, question)
accuracy = evaluate(response, sample.answer)
position_results.append(accuracy)
# 평균 성능 (위치에 강건한 성능)
results.append(np.mean(position_results))
return np.mean(results)다양한 길이 테스트
def length_aware_evaluation(model, dataset):
"""다양한 컨텍스트 길이에서 평가"""
results = {}
for num_docs in [5, 10, 20, 30]:
accuracy = evaluate_with_n_docs(model, dataset, num_docs)
results[num_docs] = accuracy
return results위치별 성능 리포트
def position_aware_evaluation(model, dataset):
"""위치별 상세 성능 분석"""
position_performance = defaultdict(list)
for sample in dataset:
for position in range(sample.num_docs):
accuracy = evaluate_at_position(model, sample, position)
position_performance[position].append(accuracy)
# 리포트 생성
report = {
'beginning': np.mean([position_performance[i] for i in range(3)]),
'middle': np.mean([position_performance[i] for i in range(7, 13)]),
'end': np.mean([position_performance[i] for i in range(-3, 0)]),
'overall': np.mean([v for vals in position_performance.values() for v in vals])
}
return report4. 실무 적용 가이드라인
언제 긴 컨텍스트가 필요한가?
적합한 경우
✅ 문서 요약
- 전체 문서를 한 번에 처리
- 위치보다 전반적 이해 중요
- 중간 내용도 요약에 포함
✅ 감정 분석
- 전체적인 톤 파악
- 특정 위치에 의존하지 않음
✅ 번역
- 순차적 처리
- 전체 문맥 고려
부적합한 경우
❌ 정보 검색 (Fact Finding)
- 특정 사실을 찾아야 함
- 위치 편향 문제 심각
- 대안: 짧은 컨텍스트 + RAG
❌ 질의응답
- 관련 정보의 정확한 위치 중요
- 중간에 있으면 놓칠 위험
- 대안: 문서 재배치 또는 분할 처리
❌ 다중 홉 추론 (Multi-hop Reasoning)
- 여러 문서에서 정보 수집 필요
- 중간 문서가 중요할 수 있음
- 대안: 계층적 처리
실무 체크리스트
긴 컨텍스트 사용 전 확인사항
- 정말로 긴 컨텍스트가 필요한가?
- 청크 분할로 해결 가능한가?
- 중요 정보의 위치를 제어할 수 있는가?
- 위치 편향을 테스트했는가?
- 대안 전략을 검토했는가?
긴 컨텍스트 사용 시 모범 사례
-
중요 정보를 양 끝에 배치
context = f""" {important_info_1} {less_important_info} {important_info_2} Question: {question} """ -
문서 수 최소화
- 질 > 양
- 상위 3-5개 문서만 사용
- 노이즈 감소
-
프롬프트에 명시적 지시
prompt = """ 주의: 아래 모든 문서를 꼼꼼히 검토하세요. 관련 정보는 어느 위치에나 있을 수 있습니다. [문서들] 질문: {question} """ -
답변 검증
- 여러 번 시도 (위치 변경)
- 일관성 확인
- 신뢰도 평가
한계점 및 도전 과제
1. 연구의 한계
평가 작업의 범위
제한적 작업
- 주로 정보 검색 중심
- 창의적 작업 미평가
- 대화형 작업 미포함
추가 연구 필요 영역
- 코드 생성 (긴 컨텍스트에서)
- 장문 작성
- 복잡한 추론 체인
모델의 다양성
평가된 모델
- 주로 2023년 초중반 모델
- Transformer 기반 위주
- 다른 아키텍처 미평가
최신 모델
- GPT-4 Turbo (128K)
- Claude 3 (200K)
- Gemini 1.5 Pro (1M)
- 이들도 위치 편향 있는지 추가 검증 필요
2. 근본 원인 불확실성
가설들
-
주의 메커니즘
- Attention 패턴 분석 필요
- 중간 토큰에 대한 주의 가중치 감소?
-
위치 인코딩
- 절대/상대 위치 인코딩의 영향
- RoPE, ALiBi 등의 효과
-
학습 데이터
- 학습 시 문서 구조 편향
- 중요 정보가 시작/끝에 있는 경향
-
모델 용량
- 표현 능력의 한계
- 정보 병목 현상
해결 방향 불명확
- 원인이 명확하지 않아 해결책 제시 어려움
- 아키텍처 수준의 변경 필요할 수 있음
3. 실무 적용의 어려움
추가 비용
계산 비용
# 기존 방식
response = llm.generate(long_context, question) # 1회 호출
# 위치 편향 완화 (다중 호출)
responses = []
for position in positions:
reordered_context = reorder(long_context, position)
response = llm.generate(reordered_context, question)
responses.append(response)
final_response = aggregate(responses) # N회 호출 (N배 비용)시간 지연
- 여러 번 호출 시 대기 시간 증가
- 실시간 서비스에 부적합
- 사용자 경험 저하
구현 복잡도
문서 재배치 로직
- 중요도 판단 알고리즘 필요
- 동적 재배치 시스템 구축
- 캐싱 전략 수립
A/B 테스트 필요
- 개선 효과 검증
- 비용 대비 효과 평가
- 도메인별 최적화
후속 연구 및 발전
1. 아키텍처 개선
Sliding Window Attention
개념
- 전체 컨텍스트가 아닌 윈도우 내에서만 attention
- 중간 정보에도 동등한 처리
예시: Longformer
# 전통적 Attention: O(n²)
attention = softmax(Q @ K.T / sqrt(d)) @ V
# Sliding Window Attention: O(n × w)
# w: 윈도우 크기
attention = sliding_window_attention(Q, K, V, window_size=512)장점
- 계산 효율성
- 균등한 정보 처리
- 위치 편향 완화 가능
Hierarchical Transformers
개념
- 청크별로 처리 후 통합
- 다층 처리 구조
구조
Input: [Doc1, Doc2, ..., Doc20]
↓
Layer 1: [Summary1, Summary2, ..., Summary4] # 5개씩 묶어 요약
↓
Layer 2: [FinalSummary] # 통합
↓
Output: Answer
장점
- 모든 문서에 동등한 주의
- 계층적 정보 통합
- 확장성
2. 학습 방법 개선
위치 인식 학습 (Position-Aware Training)
방법
def position_aware_training(model, dataset):
"""학습 시 관련 정보를 무작위 위치에 배치"""
for batch in dataset:
for sample in batch:
# 매 epoch마다 위치 무작위화
position = random.randint(0, len(sample.docs))
shuffled_docs = shuffle_docs(sample.docs, sample.answer_doc, position)
# 모델 학습
loss = model.train(shuffled_docs, sample.answer)
loss.backward()효과
- 위치에 강건한 모델 학습
- 중간 정보 활용 능력 향상
- 일반화 성능 개선
Curriculum Learning
점진적 난이도 증가
# 학습 스케줄
Stage 1: 5개 문서, 답변 위치 = 시작/끝
Stage 2: 10개 문서, 답변 위치 = 무작위
Stage 3: 20개 문서, 답변 위치 = 중간 강조
Stage 4: 30개+ 문서, 완전 무작위기대 효과
- 단계적 능력 향상
- 안정적 학습
- 최종 성능 개선
3. 새로운 평가 표준
Lost-in-the-Middle 벤치마크
제안
- 위치 편향을 체계적으로 측정하는 표준 벤치마크
- 다양한 작업 포함
- 공정한 모델 비교
포함 요소
-
다양한 작업 유형
- QA, 요약, 추론, 검색
-
다양한 길이
- 5개, 10개, 20개, 30개 문서
-
위치 무작위화
- 매 평가마다 위치 변경
- 평균 성능 측정
-
상세 리포트
- 위치별 성능
- U-곡선 시각화
- 위치 편향 점수
리더보드
기존 리더보드 문제점
- 단일 점수만 제공
- 위치 편향 정보 없음
개선된 리더보드
| 모델 | 전체 | 시작 | 중간 | 끝 | 편향 점수 |
|---|---|---|---|---|---|
| Model A | 72% | 85% | 55% | 80% | 0.35 (높음) |
| Model B | 70% | 75% | 68% | 72% | 0.10 (낮음) |
- Model B가 실제로 더 강건함
- 전체 점수만으로는 알 수 없음
4. 실용적 해결책
ReRanking 전략
개념
- 검색 후 관련성에 따라 재정렬
- 중요 문서를 양 끝에 배치
구현
def rerank_for_llm(docs, query):
"""LLM의 위치 편향을 고려한 재정렬"""
# 1. 관련성 점수 계산
scored_docs = [(doc, compute_relevance(doc, query)) for doc in docs]
sorted_docs = sorted(scored_docs, key=lambda x: x[1], reverse=True)
# 2. 재배치: 홀수는 시작, 짝수는 끝
reordered = []
for i, (doc, score) in enumerate(sorted_docs):
if i % 2 == 0:
reordered.insert(0, doc) # 시작
else:
reordered.append(doc) # 끝
return reorderedAttention Bias Correction
개념
- 모델 출력에 후처리 적용
- 중간 위치 정보에 가중치 증가
방법
def corrected_generation(model, context, query):
"""여러 위치에서 생성 후 통합"""
# 다양한 위치에서 답변 생성
answers = []
for rotation in range(3):
rotated_context = rotate_context(context, rotation)
answer = model.generate(rotated_context, query)
answers.append(answer)
# 앙상블
final_answer = voting(answers) # 또는 LLM이 최선 선택
return final_answerChunking + Map-Reduce
전략
def map_reduce_qa(docs, query):
"""청크별 처리 후 통합"""
# Map: 각 문서를 독립적으로 처리
chunk_answers = []
for doc in docs:
# 각 문서는 짧아서 위치 편향 최소화
answer = llm.generate(doc, query)
if is_relevant(answer):
chunk_answers.append(answer)
# Reduce: 답변들을 통합
if len(chunk_answers) == 0:
return "No answer found"
elif len(chunk_answers) == 1:
return chunk_answers[0]
else:
# 여러 답변을 하나로 통합
combined = llm.generate(
f"다음 답변들을 통합하세요:\n" +
"\n".join(chunk_answers) +
f"\n\n질문: {query}"
)
return combined관련 개념
- RAG 패턴
- 프롬프트 및 컨텍스트 엔지니어링 핵심 논문
- Retrieval-Augmented Generation (RAG): 문서 검색과 생성 통합
- Multi-Document QA: 여러 문서에서 답변 찾기
- Context Window: 모델이 한 번에 처리할 수 있는 입력 길이
- Attention Mechanism: Transformer의 핵심 메커니즘
- Position Encoding: 토큰 위치 정보 표현
참고 자료
- 최신 AI 연구 논문
- 학습 자료 모음
- 논문: https://arxiv.org/abs/2307.03172
- Stanford NLP Group: https://nlp.stanford.edu/
실전 가이드
Lost-in-the-Middle 문제 진단
1. 자가 진단 테스트
간단한 테스트 구현
def test_position_bias(model, sample_data):
"""
모델의 위치 편향 테스트
Args:
model: 테스트할 LLM
sample_data: [(question, answer, distractor_docs)] 형식의 데이터
Returns:
position_performance: 위치별 성능 딕셔너리
"""
position_performance = defaultdict(list)
for question, answer, distractors in sample_data:
answer_doc = f"답변: {answer}"
# 각 위치에서 테스트
for position in range(len(distractors) + 1):
# 문서 배치
docs = distractors[:position] + [answer_doc] + distractors[position:]
context = "\n\n---\n\n".join(docs)
# 모델 평가
prompt = f"{context}\n\n질문: {question}\n답변:"
response = model.generate(prompt)
# 정확도 측정
is_correct = evaluate_answer(response, answer)
position_performance[position].append(is_correct)
# 결과 요약
summary = {}
for pos, results in position_performance.items():
summary[pos] = {
'accuracy': np.mean(results),
'count': len(results)
}
return summary
# 사용 예시
results = test_position_bias(my_model, test_dataset)
# 시각화
plot_position_performance(results)결과 해석
def interpret_results(results):
"""결과 해석 및 진단"""
positions = sorted(results.keys())
accuracies = [results[p]['accuracy'] for p in positions]
# 시작/중간/끝 성능
start_acc = np.mean(accuracies[:3])
middle_acc = np.mean(accuracies[len(accuracies)//2-1:len(accuracies)//2+2])
end_acc = np.mean(accuracies[-3:])
# 진단
diagnosis = {
'has_bias': (start_acc - middle_acc) > 0.1, # 10% 이상 차이
'bias_severity': start_acc - middle_acc,
'pattern': 'U-shaped' if (start_acc > middle_acc and end_acc > middle_acc) else 'other',
'recommendation': None
}
# 권장사항
if diagnosis['bias_severity'] > 0.2:
diagnosis['recommendation'] = "심각: 문서 재배치 또는 청킹 전략 필수"
elif diagnosis['bias_severity'] > 0.1:
diagnosis['recommendation'] = "중간: 문서 수 제한 또는 재배치 권장"
else:
diagnosis['recommendation'] = "양호: 현재 방식 유지 가능"
return diagnosis2. 프로덕션 모니터링
실시간 모니터링 시스템
class PositionBiasMonitor:
"""프로덕션 환경에서 위치 편향 모니터링"""
def __init__(self, sample_rate=0.1):
self.sample_rate = sample_rate # 10% 샘플링
self.position_stats = defaultdict(lambda: {'correct': 0, 'total': 0})
def log_query(self, query, docs, predicted_answer, true_answer=None):
"""각 쿼리 로깅"""
# 샘플링 (모든 쿼리를 로깅하면 비용이 큼)
if random.random() > self.sample_rate:
return
# Ground truth가 있는 경우에만
if true_answer is None:
return
# 답변이 포함된 문서 위치 찾기
answer_position = self._find_answer_position(docs, true_answer)
if answer_position is None:
return
# 정확도 기록
is_correct = self._check_correctness(predicted_answer, true_answer)
self.position_stats[answer_position]['total'] += 1
if is_correct:
self.position_stats[answer_position]['correct'] += 1
def get_report(self):
"""주기적 리포트 생성"""
report = {}
for pos, stats in self.position_stats.items():
if stats['total'] > 0:
report[pos] = stats['correct'] / stats['total']
return report
def alert_if_biased(self, threshold=0.15):
"""편향이 심하면 알림"""
report = self.get_report()
if len(report) < 3:
return False # 데이터 불충분
positions = sorted(report.keys())
start_acc = np.mean([report[p] for p in positions[:3]])
middle_positions = positions[len(positions)//2-1:len(positions)//2+2]
middle_acc = np.mean([report[p] for p in middle_positions])
if start_acc - middle_acc > threshold:
self.send_alert(f"위치 편향 감지: 시작 {start_acc:.2%}, 중간 {middle_acc:.2%}")
return True
return False사용 예시
# 초기화
monitor = PositionBiasMonitor(sample_rate=0.1)
# RAG 시스템에 통합
def rag_with_monitoring(query):
docs = retrieve_documents(query)
answer = llm.generate(docs, query)
# 모니터링 (백그라운드)
monitor.log_query(query, docs, answer, get_ground_truth(query))
return answer
# 주기적 리포트
@schedule.every().day.at("00:00")
def daily_report():
report = monitor.get_report()
print(f"일일 위치 편향 리포트: {report}")
if monitor.alert_if_biased():
print("⚠️ 위치 편향 대응 필요!")문제 해결 전략
전략 선택 플로우차트
문서 개수는?
│
├─ ≤5개 → 위치 편향 최소 → 기본 방식 사용
│
├─ 6-10개 →
│ │
│ ├─ 중요도 판단 가능?
│ │ ├─ Yes → 재배치 전략
│ │ └─ No → 청킹 전략
│
└─ >10개 →
│
├─ 실시간 요구?
│ ├─ Yes → 문서 수 제한 (top-5)
│ └─ No → Map-Reduce 전략
│
└─ 비용 제약?
├─ 높음 → 문서 수 제한
└─ 낮음 → 다중 쿼리 + 앙상블
전략 비교표
| 전략 | 비용 | 지연시간 | 효과 | 구현 난이도 | 추천 상황 |
|---|---|---|---|---|---|
| 문서 재배치 | 낮음 | 낮음 | 중간 | 쉬움 | 중요도 판단 가능 시 |
| 문서 수 제한 | 낮음 | 낮음 | 높음 | 매우 쉬움 | 실시간, 비용 제약 |
| 청킹 | 중간 | 중간 | 높음 | 중간 | 많은 문서, 균형 |
| Map-Reduce | 높음 | 높음 | 매우 높음 | 어려움 | 정확도 최우선 |
| 다중 쿼리 | 매우 높음 | 매우 높음 | 매우 높음 | 중간 | 중요한 작업 |
구현 템플릿
1. 간단한 재배치
def simple_rerank_strategy(docs, query, relevance_scorer):
"""가장 간단한 개선 전략"""
# 관련성 점수
scored = [(doc, relevance_scorer(doc, query)) for doc in docs]
sorted_docs = sorted(scored, key=lambda x: x[1], reverse=True)
# 상위 5개만 사용
top_docs = [doc for doc, score in sorted_docs[:5]]
# 재배치: 가장 관련성 높은 것을 시작과 끝에
if len(top_docs) >= 3:
reordered = [
top_docs[0], # 가장 중요
*top_docs[2:], # 중간 중요도
top_docs[1] # 두 번째로 중요
]
else:
reordered = top_docs
return reordered2. 청킹 전략
def chunking_strategy(docs, query, llm, chunk_size=3):
"""문서를 청크로 나누어 처리"""
# 청크 생성
chunks = [docs[i:i+chunk_size] for i in range(0, len(docs), chunk_size)]
# 각 청크 처리
chunk_answers = []
for chunk in chunks:
context = "\n\n---\n\n".join(chunk)
prompt = f"{context}\n\n질문: {query}\n답변:"
answer = llm.generate(prompt)
if is_informative(answer):
chunk_answers.append(answer)
# 통합
if not chunk_answers:
return "답을 찾을 수 없습니다."
elif len(chunk_answers) == 1:
return chunk_answers[0]
else:
# 여러 답변 통합
synthesis_prompt = f"""
다음은 같은 질문에 대한 여러 답변입니다:
{chr(10).join(f"{i+1}. {ans}" for i, ans in enumerate(chunk_answers))}
질문: {query}
위 답변들을 종합하여 하나의 완전한 답변을 작성하세요.
"""
return llm.generate(synthesis_prompt)3. Map-Reduce 전략
def map_reduce_strategy(docs, query, llm):
"""완전한 Map-Reduce 구현"""
# Map Phase: 각 문서에서 관련 정보 추출
mapped_results = []
for doc in docs:
map_prompt = f"""
문서:
{doc}
질문: {query}
위 문서에서 질문과 관련된 정보를 추출하세요.
관련 정보가 없으면 "없음"이라고 답하세요.
"""
result = llm.generate(map_prompt)
if "없음" not in result:
mapped_results.append(result)
# Reduce Phase: 추출된 정보를 통합
if not mapped_results:
return "답을 찾을 수 없습니다."
reduce_prompt = f"""
다음은 여러 문서에서 추출한 정보입니다:
{chr(10).join(f"정보 {i+1}:\n{info}\n" for i, info in enumerate(mapped_results))}
질문: {query}
위 정보들을 바탕으로 질문에 대한 완전하고 정확한 답변을 작성하세요.
"""
return llm.generate(reduce_prompt)핵심 요약
Lost-in-the-Middle의 핵심 발견
-
위치 편향의 보편성
- 모든 모델에서 나타남
- 컨텍스트 길이 무관
- 근본적인 문제
-
U자형 성능 곡선
- 시작: 높은 성능
- 중간: 20-40% 저하
- 끝: 회복
-
실무적 함의
- 긴 컨텍스트 지원 ≠ 효과적 활용
- RAG 시스템 설계에 중요
- 문서 순서가 성능에 큰 영향
-
해결 방향
- 문서 재배치
- 문서 수 제한
- 청킹 및 Map-Reduce
- 아키텍처 개선 필요
실무 적용 핵심 원칙
Do’s ✅
- 중요 정보를 시작이나 끝에 배치
- 문서 수를 최소화 (top-5 권장)
- 위치 편향 테스트 수행
- 문서를 청크로 나누어 처리
- 프로덕션 모니터링 구축
Don’ts ❌
- 10개 이상 문서를 무작정 LLM에 전달
- 문서 순서를 무시
- 긴 컨텍스트만 믿고 검증 안 함
- 단일 점수로만 모델 평가
- 위치 편향 문제 간과
미래 전망
단기 (1-2년)
- 더 나은 위치 인코딩
- 학습 방법 개선
- 실무 best practice 확립
중기 (3-5년)
- 새로운 아키텍처 등장
- 위치 편향 최소화 모델
- 표준 평가 방법 확립
장기 (5년+)
- 진정한 긴 컨텍스트 활용
- 위치 무관 정보 처리
- 인간 수준 문서 이해