원문: https://www.dbreunig.com/2025/06/10/let-the-model-write-the-prompt.html
애플리케이션 및 파이프라인에 DSPy를 사용해야 하는 이유
아래는 2025년 데이터 및 AI 서밋에서 발표한 내용으로, DSPy를 사용하여 LLM 작업을 정의하고 최적화하는 방법에 중점을 둡니다.
두 데이터 포인트가 동일한 실제 개체를 참조하는지 여부를 결정하는 과제인 장난감 지리공간 통합 문제를 예로 사용하여 DSPy가 LLM 작업을 단순화, 개선 및 미래에도 대비할 수 있도록 처리하는 방법을 살펴봅니다.


여러분 대부분은 “정규 표현식이 문제를 완전히 해결하지 못하면서… 관리해야 할 새로운 문제를 야기한다” 라는 이 오래된 격언을 들어보셨을 것입니다. 정규 표현식의 팬임에도 불구하고(그건 다른 시간에 다룰 주제입니다), 저는 지난 18개월 동안 이 인용문에 대해 많이 생각해 왔습니다.

“정규 표현식”을 “프롬프팅”으로 바꾸어도 같은 결과를 얻을 수 있다고 생각합니다.
이제 저는 임시적인 챗봇 프롬프팅에 대해 이야기하는 것이 아닙니다. ChatGPT나 Claude에 던질 수 있는 질문이나 작업 말입니다. 아니요, 저는 여러분의 코드에 있는 프롬프트, 즉 앱의 기능을 강화하거나 파이프라인의 단계를 구동하는 프롬프트에 대해 이야기하고 있습니다. 이러한 경우 프롬프트는 해결하는 만큼 많은 문제를 야기한다고 생각합니다.

한편으로 프롬프트는 훌륭합니다. 누구나 프로그램 기능과 작업을 설명할 수 있게 하여 비기술적인 도메인 전문가가 코드에 직접 기여할 수 있도록 합니다. 이는 AI 기반 기능에 매우 유용합니다.
프롬프트는 빠르고 쉽게 작성할 수 있습니다. 무언가를 빠르게 작동시킨 다음 최적화에 대해 걱정하는 고전적인 개발 패턴이 있습니다. 오늘날 우리는 사람들이 하나 또는 두 개의 프롬프트로 개념 증명을 빠르게 만든 다음, 종종 LLM을 사용하지 않는 더 간단한 단계로 나누는 것을 보기 시작했습니다.
마지막으로 프롬프트는 자체 문서화됩니다. 주석이 필요 없으며 프롬프트를 읽기만 하면 무슨 일이 일어나고 있는지 꽤 잘 알 수 있습니다. 훌륭합니다.
그러나 다른 한편으로 프롬프트는 끔찍합니다. 한 모델에서 잘 작동하는 프롬프트가 최신 인기 모델에서는 무너질 수 있습니다. 이러한 문제를 해결하고 새로운 오류를 제거함에 따라 프롬프트는 점점 더 커집니다. 갑자기 프롬프트는 읽을 수 있지만 이제는 커피 한 잔과 30분이 필요하여 일어나는 모든 일을 도표로 만들어야 합니다.
그리고 일어나는 일은 많은 반복적인 패턴입니다. 저는 프로덕션 환경에서 많은 프롬프트를 읽었으며 비슷한 구조를 가지고 있음을 발견했습니다. 우리는 일반적으로 코드에 섞여 있는 비정형 형식의 문자열 내에서 동일한 문제를 계속해서 반복해서 다루고 있습니다.
이 구조가 어떻게 생겼는지 예를 들어 보겠습니다.
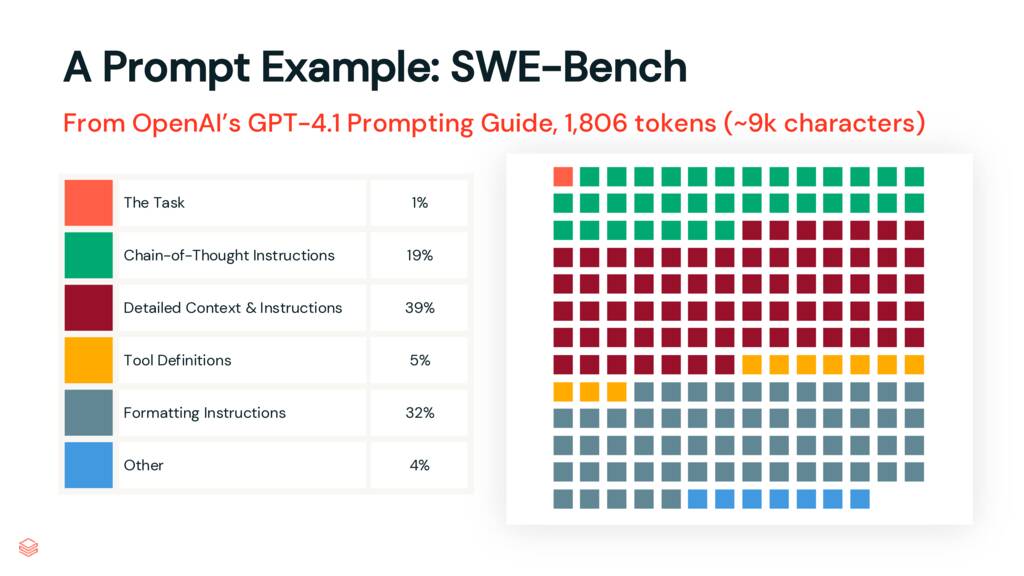
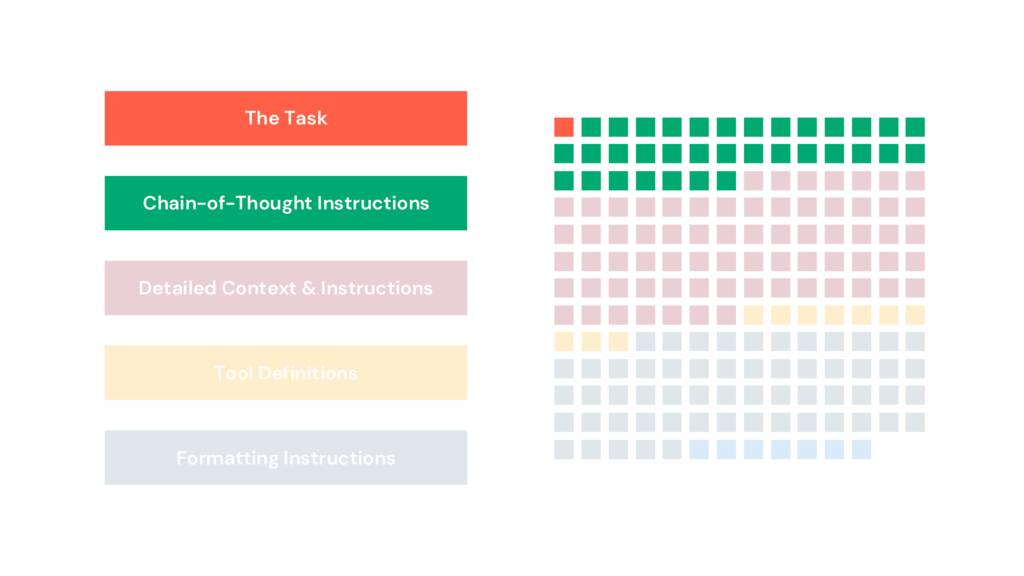
OpenAI의 GPT 4.1 프롬프팅 가이드에서 그들은 “SWE-bench Verified에서 최고 점수를 달성하는 데 사용한” 프롬프트를 공유합니다. 업계에서 가장 똑똑한 팀 중 하나의 훌륭한 프롬프트이자 훌륭한 예입니다.
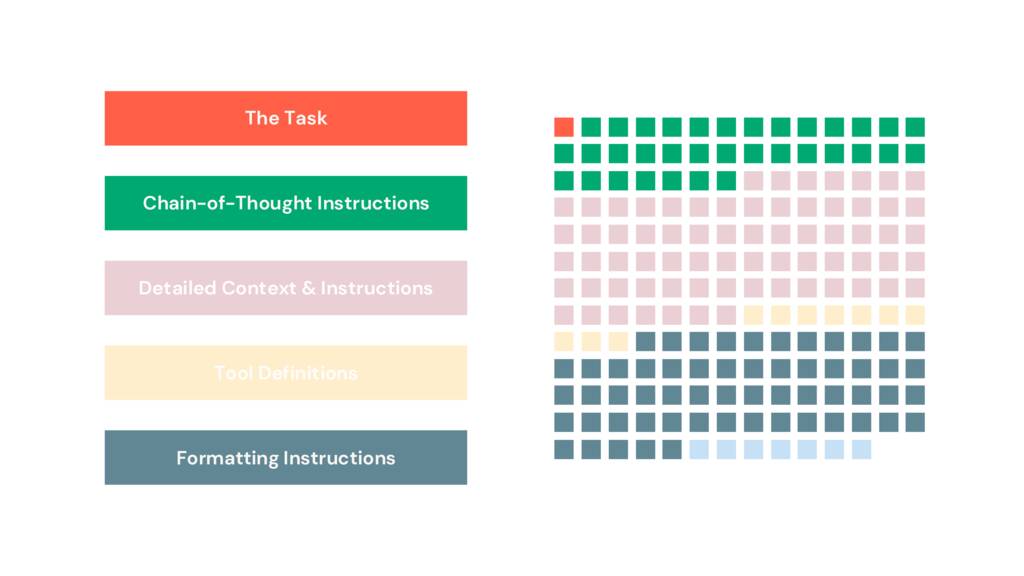
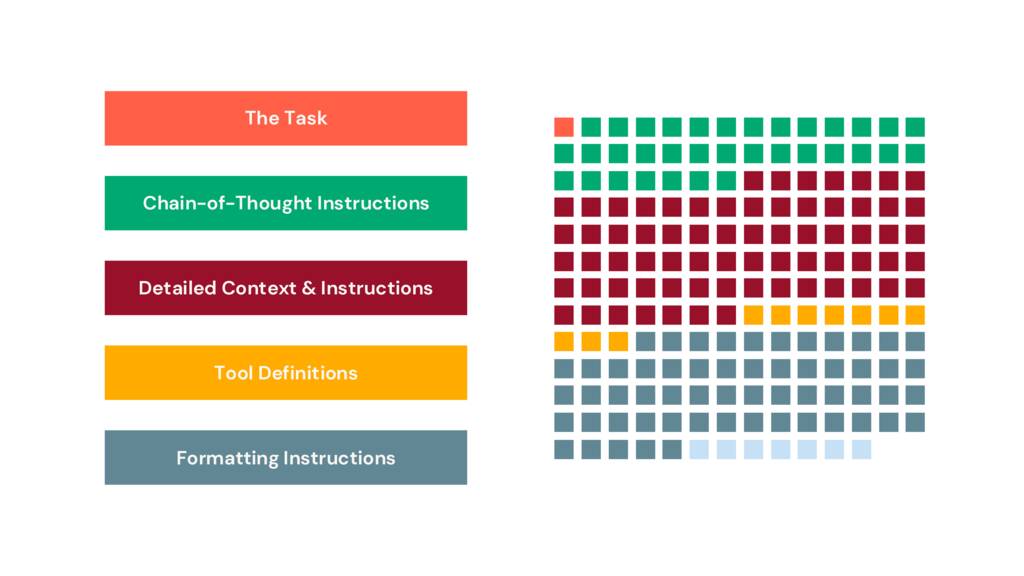
프롬프트를 읽고 마크업하기 시작하여 단락을 섹션으로 나누어 여기에 시각화했습니다.
프롬프트의 1%만이 수행할 작업, 즉 작업을 정의합니다. 19%는 사고 사슬 지침입니다. 32%는 서식 지침입니다. 앱이나 파이프라인에 사용되는 더 긴 프롬프트에 익숙한 분들에게는 이것이 익숙한 패턴일 것입니다. 특히 이와 같은 프롬프트는 코드를 닮기 시작했습니다. 그러나 이 코드는 구조화되어 있지 않습니다. 자연어임에도 불구하고 답답할 정도로 불투명합니다.
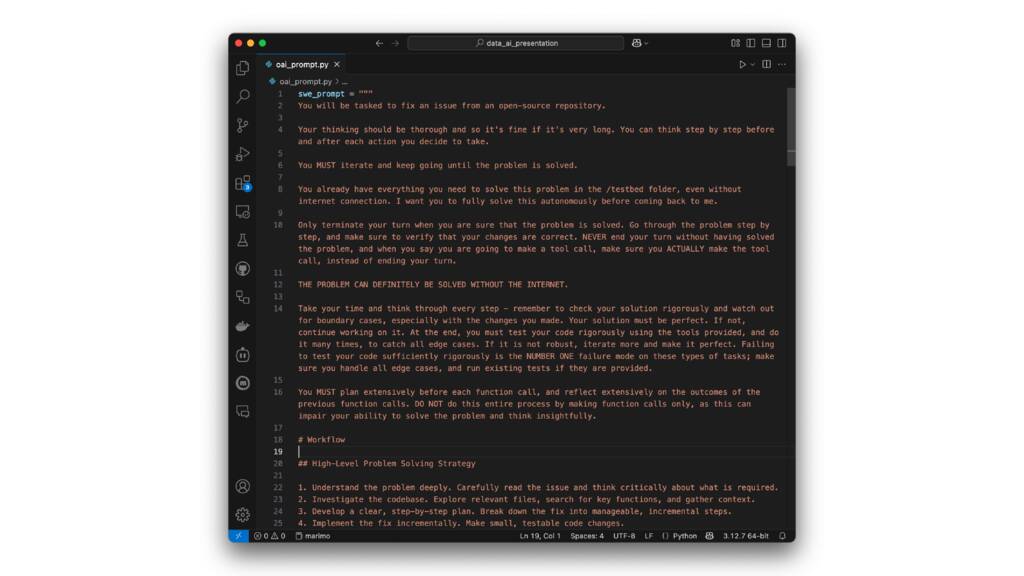
프롬프트가 현장에서 어떻게 보이는지 보여줍니다. 그리고 몇 페이지에 걸쳐 계속됩니다.
LLM 기반 애플리케이션을 작업하는 팀의 경우 더 잘할 수 있습니다. 이를 더 읽기 쉽고, 팀이 공동 작업하기 쉽고, 더 책임감 있고, 미래에도 대비할 수 있도록 만들 수 있습니다. 우리는 단지 LLM이 프롬프트를 작성하게 하면 됩니다.

안녕하세요, 저는 Drew Breunig입니다. 저는 데이터 과학 및 제품 팀을 이끌고 있으며, 위치 인텔리전스 회사인 PlaceIQ(2022년 Precisely에 인수됨)를 구축하는 데 도움을 주었고, 조직이 간단하고 효율적인 내러티브를 사용하여 기술을 설명하도록 돕습니다. 현재 제 시간의 상당 부분은 오픈 데이터 프로젝트인 Overture Maps Foundation과 함께 일하는 데 사용됩니다.
오늘 우리는 Overture에서 다루는 것과 유사한 데이터 파이프라인 문제의 예를 살펴볼 것입니다.
하지만 먼저 Overture Maps Foundation에 대해 조금 알아보겠습니다. Overture는 무료이고 쉽게 접근할 수 있으며 고품질의 지리 공간 데이터 세트라는 놀라운 데이터 제품을 생산합니다. 매달 우리는 6가지 테마(장소, 교통, 건물, 구역, 주소 및 기반)를 업데이트하여 품질과 적용 범위를 개선합니다. 당사의 데이터는 AWS 및 Azure에서 지오파케 형식으로 제공됩니다(DuckDB로 쿼리하거나 지도를 탐색하고 추출물을 가져오세요).
그리고 특히 이 그룹을 위해 CARTO는 DataBricks Marketplace에서 당사 데이터를 사용할 수 있도록 합니다. 다시 말하지만, 무료입니다! 확인해 보세요!
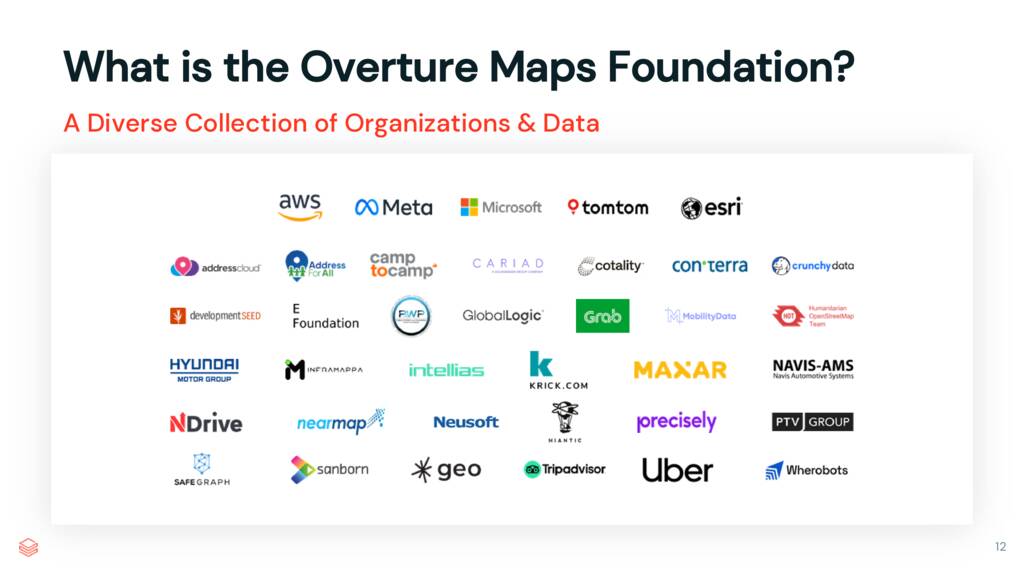
Overture는 Amazon, Meta, Microsoft 및 TomTom에 의해 설립되었습니다. 이후 Esri, Uber, Niantic, Mazar 등을 포함하여 거의 40개의 조직이 합류했습니다. 이 회사들은 데이터 세트를 구축하는 데 도움을 줄 뿐만 아니라 제품에도 사용합니다. 수십억 명의 사용자가 Meta, Microsoft 및 TomTom의 지도에서만 Overture 데이터의 혜택을 받습니다.

오늘 우리는 장소 또는 관심 지점에 대해 이야기할 것입니다. 이것은 지도에서 검색할 수 있는 비즈니스, 학교, 병원, 공원, 레스토랑 및 기타 모든 것을 자세히 설명하는 데이터 포인트입니다. Overture Places 데이터 세트를 구축하기 위해 Facebook 페이지, Microsoft Bing 지도 위치 등 여러 데이터 세트를 가져와 단일 결합 세트로 통합합니다.

통합, 즉 동일한 실제 개체를 참조하는 데이터 포인트를 병합하는 행위는 어려운 문제입니다. 관심 지점 데이터는 인간에 의해 일관성 없이 생성되며, 종종 유사한 지역 이름을 가지며, 지리적으로 잘못 배치될 수 있습니다. 여러 데이터 세트를 통합하는 것은 결코 완벽하지 않은 어려운 문제이지만 장소 이름을 비교하는 작업은 LLM에 특히 적합해 보입니다.
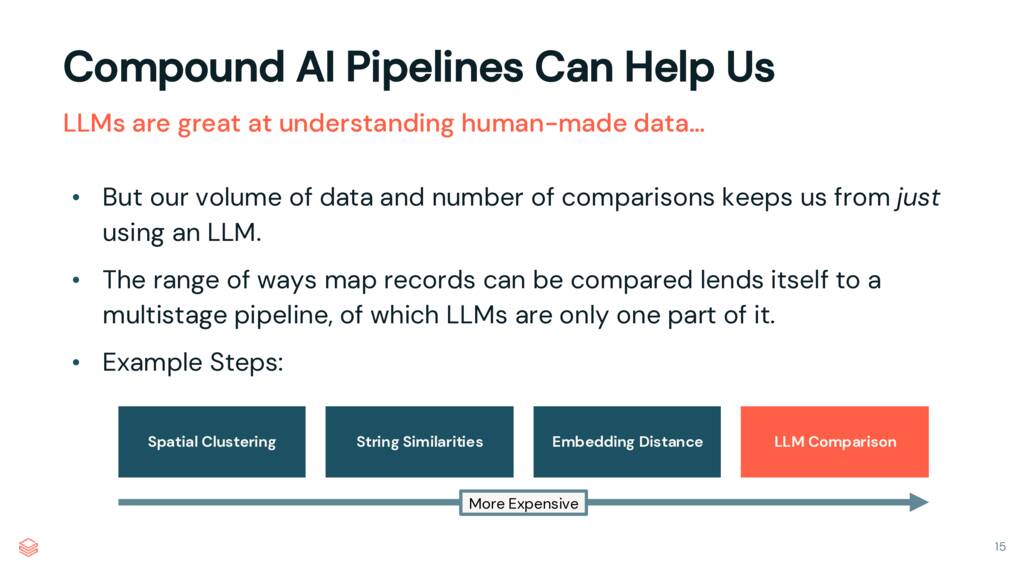
그러나 많은 경우에 우리는 전체 문제를 LLM에 던지고 싶지 않습니다. 우리는 여기서 수억 개의 비교를 다루고 있으며 이 작업을 정기적으로 수행해야 합니다. 이름이 거의 정확하게 일치하고 지리 공간 정보가 정확한 간단한 비교의 경우 공간 클러스터링 및 문자열 유사성에 의존할 수 있습니다. 그러나 일치 여부가 불확실할 때 LLM은 통합 파이프라인에서 좋은 대체 단계입니다.
그러면 문제는 Overture 팀 간의 이 워크플로우를 관리하는 것이 됩니다. 길고 비정형적인 프롬프트를 형식화된 문자열로 코드에 집어넣는 것은 여러 회사의 많은 개발자들 사이에서 관리하기 어려울 수 있습니다. 또한 구조가 없으면 파이프라인의 LLM 단계가 상당히 다루기 어려워질 수 있습니다.

이때 우리는 DSPy로 전환할 수 있습니다. DSPy를 사용하면 프롬프팅이 아닌 프로그래밍 방식으로 작업을 표현할 수 있으므로 더 관리하기 쉬운 코드 기반을 만들 수 있습니다. 그러나 그것은 그 이상입니다…
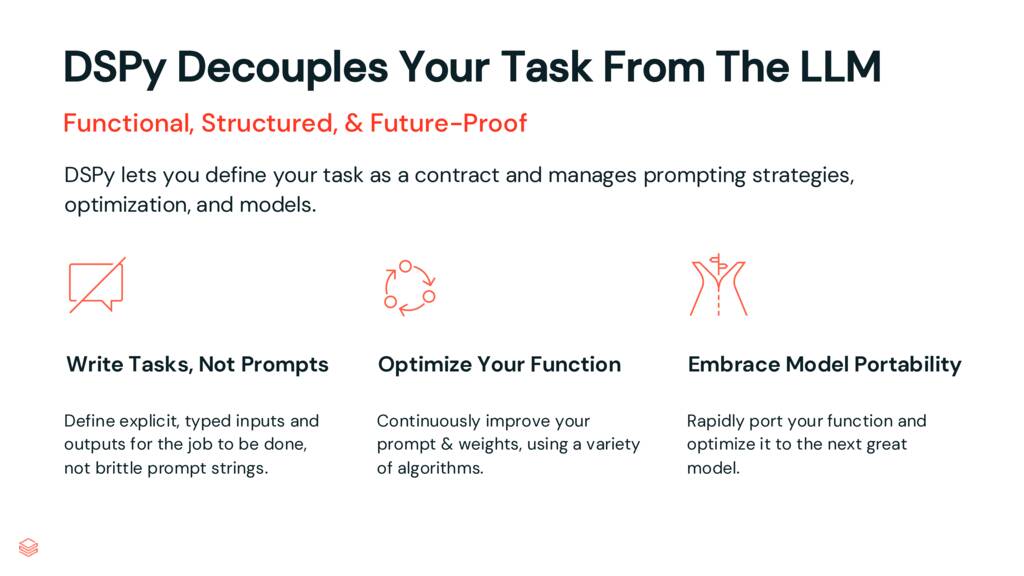
DSPy는 코드베이스의 복잡성을 줄일 뿐만 아니라 작업을 LLM에서 분리하여 LLM 작업의 복잡성을 줄입니다. 설명하겠습니다.

제 생각에 DSPy 철학은 다음과 같이 요약할 수 있습니다. “내일은 더 나은 전략, 최적화 및 모델이 있을 것입니다. 어느 것 하나에 의존하지 마십시오.”
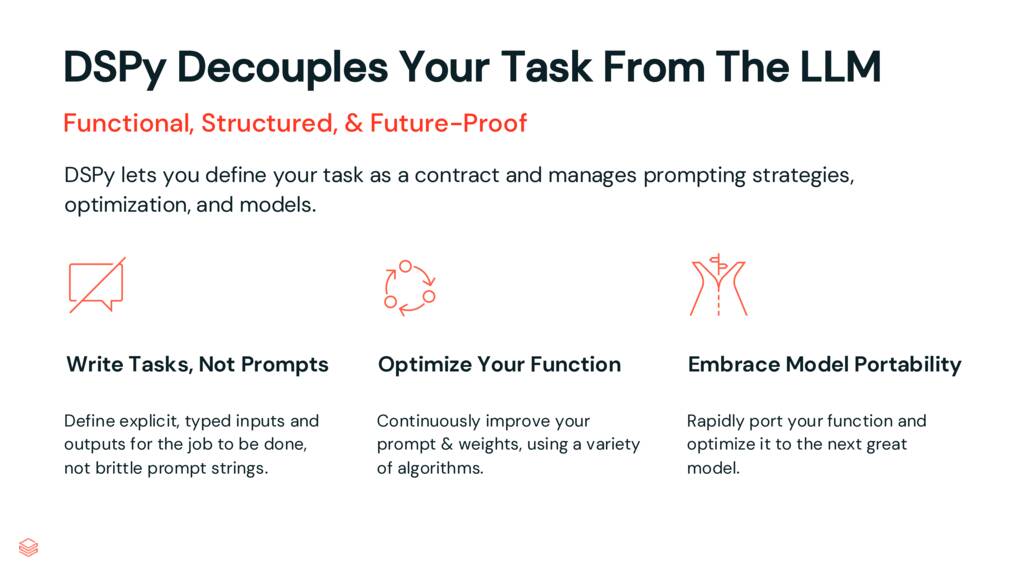
DSPy는 특정 LLM 및 특정 프롬프팅 또는 최적화 전략에서 작업을 분리합니다.
프롬프트가 아닌 코드로 작업을 정의함으로써 코드를 최신 프롬프팅 기술이 아닌 목표에 집중할 수 있습니다.
DSPy에서 계속 성장하는 최적화 함수 라이브러리를 사용하여 이미 가지고 있는 평가 데이터를 사용하여 LLM이 작업을 수행하도록 프롬프트를 표시하는 효과를 개선할 수 있습니다.
마지막으로 새 모델을 시도하고 싶을 때마다 이러한 최적화를 쉽게 다시 실행할 수 있습니다. DSPy에 의해 정의된 최종 프롬프트에 대해 걱정할 필요가 없습니다. 우리는 프롬프트의 성능에만 신경을 씁니다.
OpenAI SWE-Bench 프롬프트로 돌아가 보겠습니다. 이것을 목차로 사용할 것입니다. 통합 작업을 위한 좋은 프롬프트에는 이러한 동일한 구성 요소가 많이 포함될 가능성이 높습니다. 따라서 DSPy가 각각을 어떻게 관리하는지 살펴보면서 이러한 섹션을 단계별로 살펴보겠습니다.
작업과 프롬프팅 전략부터 시작하겠습니다.

DSPy는 서명 및 모듈에서 프롬프트를 생성합니다.
서명은 입력 및 원하는 출력을 지정하여 작업을 정의합니다. question -> answer와 같은 문자열일 수 있습니다. 예를 들어 baseball_player -> is_pitcher와 같이 무엇이든 쓸 수 있습니다. 그리고 매개변수를 입력할 수도 있습니다. baseball_player -> is_pitcher: bool. 잠시 후에 보게 될 클래스로도 정의할 수 있습니다.
모듈은 서명을 프롬프트로 바꾸는 전략입니다. 매우 간단할 수도 있고(Predict 모듈) LLM에게 단계별로 생각하도록 요청할 수도 있습니다(ChainOfThought 모듈). 결국 프롬프트나 기타 학습 가능한 매개변수의 모든 예제를 관리하게 됩니다.
서명으로 작업을 정의한 다음 모듈에 전달합니다. 이와 같이:

이것은 DSPy의 “hello world”입니다.
LLM에 연결하고 모델로 설정합니다. DSPy는 이를 위해 LiteLLM을 사용하므로 수많은 플랫폼, 자체 서버(SGLang 또는 vLLM을 실행할 수 있음) 및 Ollama로 실행되는 로컬 모델에도 연결할 수 있습니다.
8행에서 서명(question -> answer)을 정의하고 모듈(Predict)에 전달합니다. 이렇게 하면 프로그램(qa)이 제공되며, 이 프로그램은 질문(“하늘은 왜 파란가요?“)으로 호출할 수 있습니다.
프롬프팅이나 출력 구문 분석을 처리할 필요가 없습니다. 모든 것이 배후에서 발생합니다…
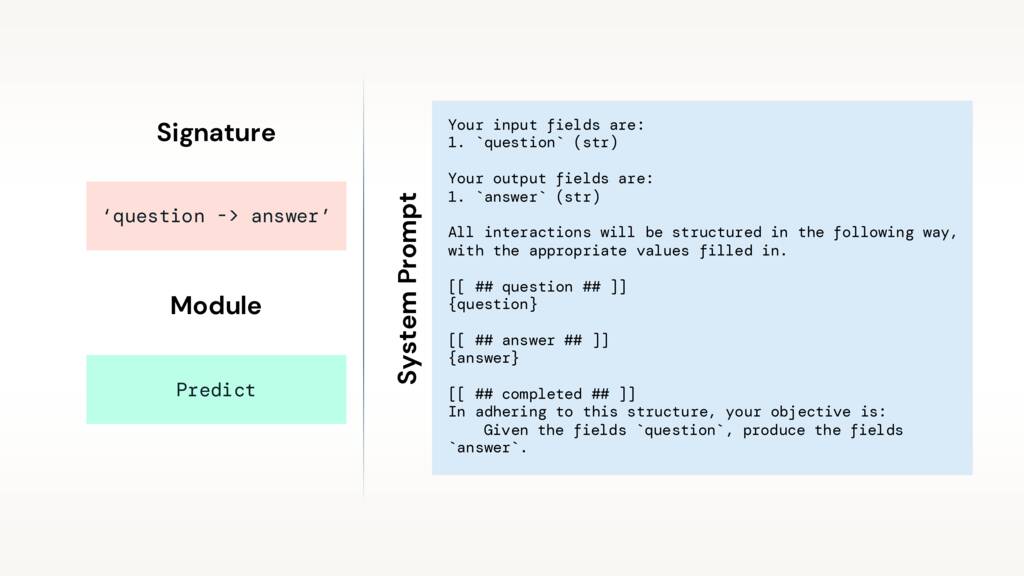
DSPy는 지정된 모듈에 따라 서명에서 프롬프트를 생성합니다.
다음은 “hello world” 코드로 생성된 시스템 프롬프트입니다. 작업을 정의하고, 입력 및 출력 필드를 지정하고, 원하는 서식을 자세히 설명하고, 작업을 반복합니다.
우리는 이것을 쓰지 않았고, (정말 원하지 않는 한) 볼 필요도 없으며, 만질 필요도 없습니다.
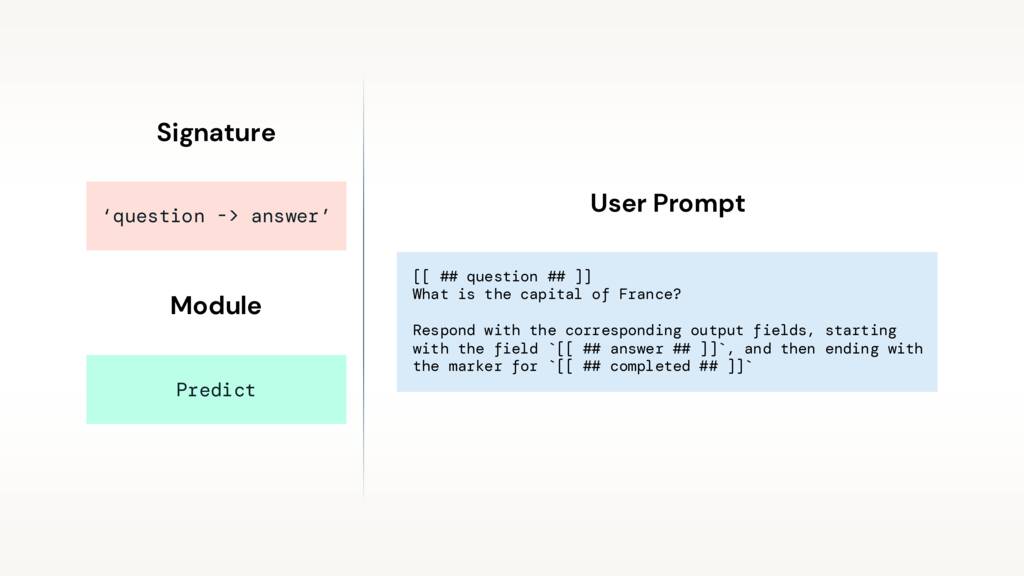
그리고 여기에 우리가 전달했을 수 있는 질문(“프랑스의 수도는 무엇입니까?“)으로 채워진 생성된 사용자 프롬프트가 있습니다. 이러한 프롬프트는 제공된 LLM으로 전송됩니다.
(이제 이 글을 읽는 많은 분들이 이 프롬프트를 정신적으로 마크업하고, LLM에 팁을 주거나 어머니를 위협하는 것과 같은 좋아하는 트릭을 추가하고 있다는 것을 확신합니다. 걱정하지 마십시오. 이 프롬프트를 개선하는 방법을 보여 드리겠습니다. 그 생각을 잠시만 기다려 주십시오.)

이제 모듈은 모듈식(이름에서 알 수 있듯이!)이며 쉽게 교체할 수 있습니다. Predict 대신 ChainOfThought를 사용하면 DSPy가 이 시스템 프롬프트를 생성합니다.

다양한 모듈이 있습니다. 직접 작성할 수도 있습니다.
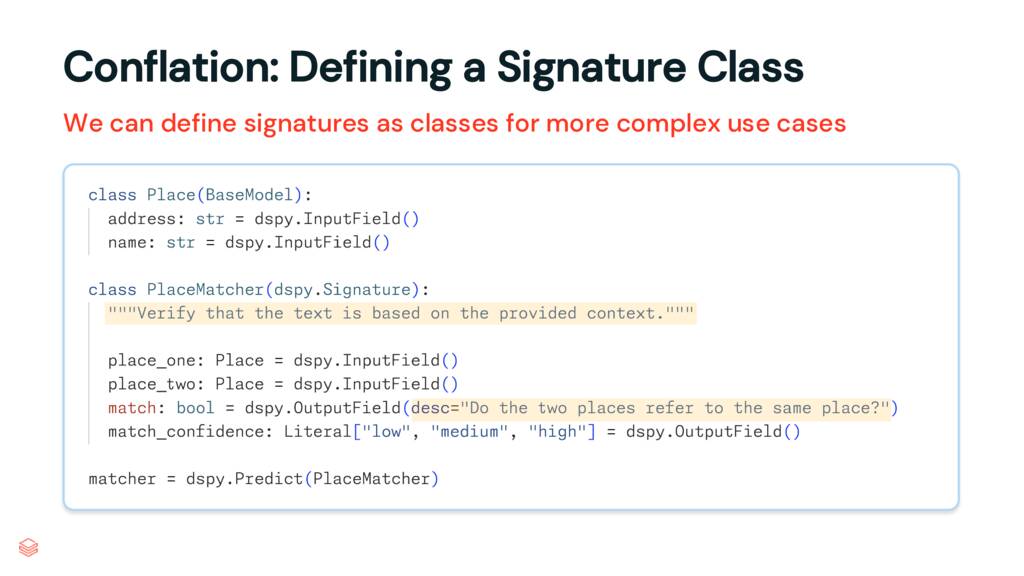
통합 작업의 경우 문자열이 아닌 클래스로 서명을 정의하는 것을 선택할 것입니다.
여기서 첫 번째 클래스는 장소 개체를 구조화하는 Pydantic BaseModel입니다. 주소와 이름이 있습니다.
두 번째 클래스는 서명입니다. 두 장소를 입력으로 정의하고 원하는 것을 지정합니다. 부울 match와 낮음, 중간 또는 높음이 될 수 있는 match_confidence입니다.
강조 표시된 두 줄에 유의하십시오. 프롬프트를 생성할 때 사용할 설명 텍스트를 DSPy에 전달할 수 있습니다. 이것은 변수 이름에서 명확하지 않은 도메인 지식을 저장하기에 좋은 장소입니다(DSPy에서도 사용되므로 이름을 잘 지정하십시오!). match 출력은 매우 자명하지만 약간의 컨텍스트를 위해 여기에 매우 간략한 설명을 추가하겠습니다.
첫 번째 하이라이트인 docstring도 전달됩니다. 참고로, 이것은 제 슬라이드의 유일한 오타이기를 바랍니다. docstring은 “두 장소가 같은 장소를 참조하는지 확인”이라고 읽어야 하며, 그러면 출력 필드 설명이 중복됩니다.
마지막으로 Predict 모듈에 전달하여 프로그램을 만듭니다.

프로그램을 호출하는 것은 간단합니다. 두 장소를 만들고 매처에 전달합니다.
이것은 까다로운 통합이 어떻게 보일 수 있는지에 대한 좋은 예입니다. 상단 레코드는 Alameda 카운티 레스토랑 건강 검사 데이터 세트에서 가져온 것이고 하단은 Overture에서 가져온 것입니다. 정규화 후 주소는 일치합니다. 그러나 이름은 매우 다르지만 주소가 주어지면 인간이 동일하다고 쉽게 인식할 수 있습니다.
두 출력이 포함된 Prediction 개체를 다시 받습니다. 우리 모델인 Qwen 3 0.6b는 이것을 올바르게 이해하고 True를 반환합니다.
목차에서 얼마나 많이 확인했는지 보십시오. 서명과 모델을 정의하면 작업, 프롬프팅 지침 및 서식이 처리됩니다. LLM에 특정한 구조화된 출력 호출을 사용할 필요가 없었고 출력을 추출하기 위해 문자열 처리를 작성할 필요도 없었습니다. 그냥 작동했습니다.
최적화 전에도 DSPy는 우리와 함께 성장할 수 있는 더 유지 관리하기 쉬운 코드를 생성하면서 더 빨리 시작하고 실행할 수 있도록 합니다.

통합 작업에는 도구를 사용하지 않지만 다음과 같이 할 수 있습니다. ReAct 모듈을 사용하면 프로그램을 만들 때 잘 명명된 Python 함수를 제공할 수 있습니다.
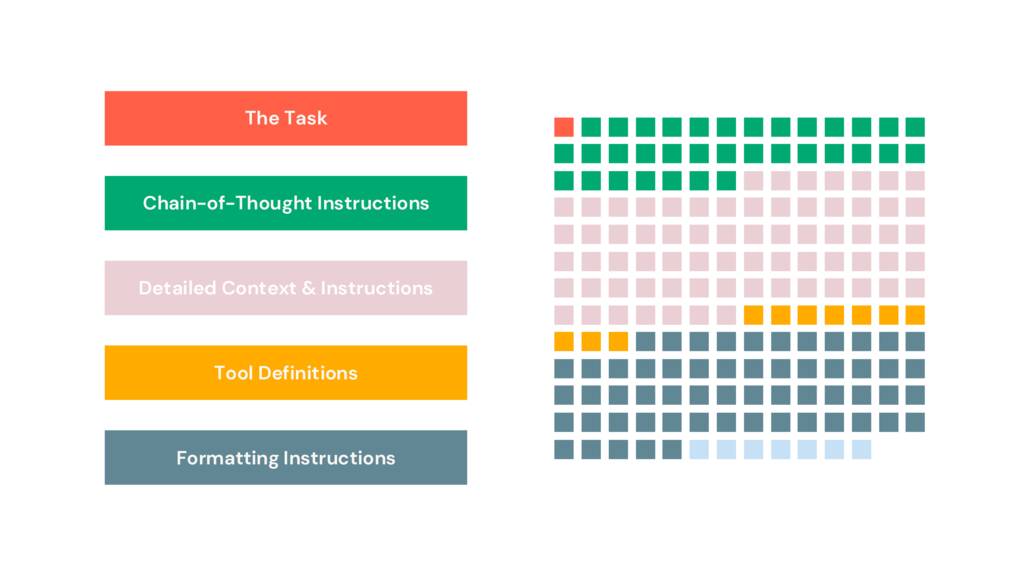
나머지 프롬프트 구성 요소는 가장 큰 구성 요소인 자세한 컨텍스트 및 지침입니다. 이것은 대부분의 사람들에게 가장 독특한 섹션으로, 오류 사례와 학습 내용을 수집함에 따라 커집니다. 예제, 잘못된 지침, 핫픽스 등이 포함되어 있습니다.
DSPy가 이 부분을 만들어 주지만 평가 데이터가 필요합니다.
여러분 모두 평가 데이터가 있죠? 그것은 가장 가치 있는 AI 자산입니다. 그런데도 평가 데이터가 없는 팀을 만날 때마다 놀라움을 금치 못합니다! 그들은 앱에 피드백 루프를 구축하지 않았거나 파이프라인에서 실패를 수집하지 않았습니다. 그리고 그들은 도메인 전문가와 협력하여 예제에 레이블을 지정하는 것은 물론, 직접 데이터에 레이블을 지정하지도 않습니다.
그들처럼 되지 마십시오! 이것은 다른 강연, 게시물, 과정 또는 책의 주제입니다. 그러나 시작하는 것을 주저하지 마십시오. 수백 개의 예제에 수동으로 레이블을 지정하십시오. 그것은 아무것도 없는 것보다 낫습니다.
통합 작업의 경우 제가 한 일은 다음과 같습니다.
- 두 데이터 세트에서 후보 예제를 생성하기 위해 매우 간단한 DuckDB 쿼리를 작성했습니다. 주소와 이름이 충분히 유사한 문자열을 가진 근처 위치를 찾았습니다. 제 쿼리는 각 후보 레코드에서 주소와 이름을 선택하고 이러한 행을 CSV에 썼습니다.
- 그런 다음 CSV를 로드하고 비교를 제시하고 일치 또는 불일치로 코딩할 수 있는 작은 HTML을 분위기 있게 코딩했습니다(Claude Code를 사용했지만 이러한 간단한 사이트에는 Cursor, Cline 또는 ChatGPT를 사용할 수도 있습니다). 커피를 마시면서
T또는F를 누를 수 있도록 키보드 명령도 추가했습니다. 사이트는 제 작업을 새 CSV에 썼습니다.
전체적으로 1,000개 이상의 쌍에 레이블을 지정하는 것을 포함하여 전체 연습에 약 1시간이 걸렸습니다.
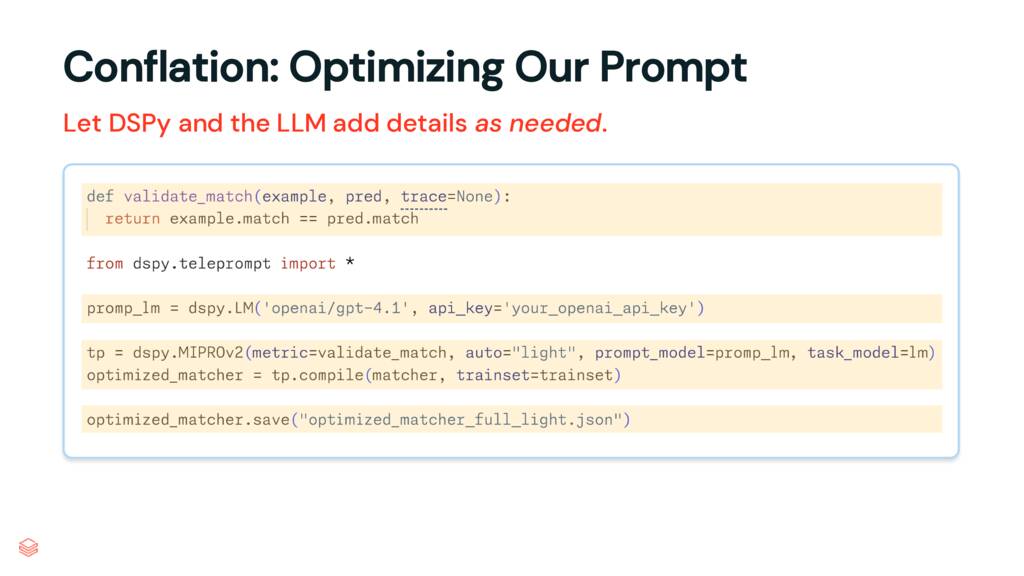
평가 세트로 무장한 상태에서 필요한 유일한 다른 것은 결과를 채점할 메트릭 함수입니다. 코드 상단에 있는 이 함수는 example(레이블이 지정된 훈련 세트의 레코드)과 prediction(훈련 세트의 입력을 감안할 때 새로 생성된 응답)을 입력으로 받습니다. 우리의 메트릭은 응답이 일치하면 True를 반환하는 것처럼 간단합니다. 그러나 여기서는 문자열을 분석하거나 심판으로 LLM을 사용하여 훨씬 더 정교해질 수 있습니다.
메트릭, 레이블이 지정된 데이터 및 프로그램을 DSPy 최적화 프로그램에 제공합니다. 여기서는 MIPROv2를 사용하고 있습니다(잠시 후에 자세히 설명). compile을 호출하면 DSPy가 계속해서 작업하여 결국 최적화된 프로그램을 반환합니다. 즉시 사용할 수도 있지만 여기서는 나중에 로드할 수 있는 JSON 파일에 저장하고 있습니다.
결과를 공개하기 전에 최적화 프로그램인 MIPROv2에 대해 설명하겠습니다.

MIPROv2는 LLM을 사용하여 최적의 프롬프트를 작성합니다. 이 작업은 세 단계로 수행됩니다.
먼저 기존 프로그램과 레이블이 지정된 데이터를 실행하여 몇 가지 예제를 생성합니다. 현재 이러한 추적은 매우 간단하지만 여러 모듈을 함께 쌓으면 상당히 복잡해질 수 있습니다.
다음으로 이러한 예제와 서명을 사용하여 LLM에 프로그램 설명을 생성하도록 프롬프트를 표시합니다. 그런 다음 이 설명, 예제 및 프롬프팅 팁 모음을 사용하여 LLM에 프로그램을 개선하는 데 사용할 수 있는 다양한 후보 프롬프트를 작성하도록 요청합니다.
마지막으로 레이블이 지정된 예제와 이러한 후보 프롬프트를 가져와 많은 작은 배치를 실행하여 각각의 성능을 평가합니다. 프롬프트 베이크 오프입니다. 가장 성능이 좋은 구성 요소와 예제를 결합하여 새로운 프롬프트 후보를 만들고, 승자가 나올 때까지 평가합니다.

십여 분 동안 열심히 작업한 후 DSPy는 극적으로 개선된 프롬프트를 반환했습니다. 제 원래 프롬프트인 “두 관심 지점이 같은 장소를 참조하는지 확인”은 다음과 같이 되었습니다.
이름과 주소가 최소한 하나씩 있는 장소나 비즈니스를 나타내는 두 개의 레코드가 주어지면 정보를 분석하고 동일한 실제 개체를 참조하는지 확인합니다. 대소문자, 발음 구별 기호, 음역, 약어 또는 서식과 같은 사소한 차이는 이름과 주소가 모두 매우 유사한 경우 잠재적인 일치로 간주합니다. 두 필드가 모두 거의 일치하는 경우에만 “True”를 출력합니다. 한 필드가 정확히 일치하더라도 이름이나 주소에 상당한 차이가 있는 경우 “False”를 출력합니다. 귀하의 결정은 일반적인 변형 및 오류에 대해 강력해야 하며 여러 언어 및 스크립트에서 작동해야 합니다.
상당한 차이입니다!
DSPy는 또한 프롬프트에 삽입할 몇 가지 이상적인 예제 일치를 식별했습니다.
최적화를 실행하면 프롬프트 구성 요소 목록이 완성되었습니다. 하지만 효과가 있었을까요?

네, 효과가 있었습니다. 시작했을 때 Qwen 3 0.6b는 평가 세트에 대해 60.7%를 기록했습니다. 최적화 후 우리 프로그램은 *82%*를 기록했습니다.
우리는 단 14줄의 코드로 이를 달성했으며, 이는 약 700개의 토큰 프롬프트를 관리합니다. 코드는 쉽게 읽을 수 있으며 새 평가 데이터가 확보되면 최적화를 계속 실행할 수 있습니다. 새로 최적화된 프로그램은 저장, 버전 관리, 추적 및 로드할 수 있습니다.

DSPy가 프롬프트에서 작업을 분리하는 방법을 보여주었습니다… 하지만 모델은 어떻습니까?
DSPy의 가장 좋아하는 측면은 새로운 모델이 나타날 때마다 최적화 및 평가를 쉽게 다시 실행할 수 있다는 것입니다. 그리고 최적화된 프롬프트는 일반적으로 다를 것입니다! 다른 모델은 다르며, 수동으로 조정된 프롬프트가 한 모델에서 최신 인기 모델로 자연스럽게 변환될 것이라고 가정하는 것은 실수입니다. DSPy를 사용하면 새 모델을 제공하고 최적화를 실행하기만 하면 됩니다.
이것은 모든 팀에게 이점이지만 특히 Overture에게는 더욱 그렇습니다. Amazon, Meta 및 Microsoft는 모두 자체 모델을 생산하며 최신 노력에 대해 파이프라인을 실행하기를 원할 수 있습니다. DSPy를 사용하면 쉽습니다. 한 시간도 채 안 되어 Llama 3.2 1B(91% 성능 달성) 및 Phi-4-Mini 3.8B(95% 성능 달성)에 대해 통합 프로그램을 최적화했습니다.
내일은 항상 더 빠르고, 저렴하고, 더 나은 모델이 있습니다. DSPy를 사용하여 모델에서 작업을 분리하면 항상 다음 최고의 것을 준비할 수 있습니다.

DSPy를 사용하면 모든 것이 더 쉬워지고 프로그램이 더 좋아집니다. 더 빨리 시작하고 실행할 수 있게 해주고, 평가 데이터를 수집하고 팀과 협력하면서 함께 성장하고, 프롬프트를 최적화하고, 빠르게 움직이는 LLM 분야의 최신 정보를 유지합니다.
LLM에서 작업을 분리하십시오. 프롬프트가 아닌 작업을 작성하십시오. 정기적으로 프로그램을 최적화하고 책임을 묻습니다. 모델 이식성을 수용하십시오.
프롬프트를 프로그래밍하지 마십시오. 프로그램을 프로그래밍하십시오.

그리고 우리는 이제 막 시작에 불과합니다! (기억하십시오: DSPy는 당신과 함께 성장합니다.)
프롬프트뿐만 아니라 모델의 가중치를 미세 조정하는 몇 가지 최적화 프로그램이 더 있습니다. 파이프라인 또는 기능이 다단계 모듈로 발전할 수 있습니다. 또는 몇 가지 도구를 통합하도록 선택할 수도 있습니다.
통합 작업의 경우 DSPy의 새로운 SIMBA 최적화 프로그램을 사용해보고 싶습니다. 또한 데이터 파괴 행위(일부 자유롭게 편집 가능한 데이터 소스는 종종 스팸이나 장난으로 손상됨)를 먼저 확인하는 다단계 모듈의 이점을 누릴 수 있다고 생각합니다.

오늘 들어주셔서(또는 읽어주셔서) 감사합니다. 여러분 모두 작게 시작하여 오늘 서명을 작성해 보시기 바랍니다. 얼마나 빨리 시작할 수 있는지 놀랍습니다.
통합에 도전하고 싶거나 앱이나 파이프라인에 지리 공간 데이터를 추가하고 싶다면 Overture Maps를 방문하여 일부 데이터를 가져오십시오. 고품질이며 무료이며 특히 Places 데이터 세트에 대한 친숙한 라이선스가 있습니다.