이 가이드는 LangGraph의 Graph API 기본 사항을 설명합니다. 상태부터 시작하여 시퀀스, 브랜치, 루프와 같은 일반적인 그래프 구조를 구성하는 방법을 다룹니다. 또한 맵-리듀스 워크플로를 위한 Send API와 상태 업데이트를 노드 간 “이동”과 결합하는 Command API 같은 LangGraph의 제어 기능도 다룹니다.
설정
langgraph를 설치하세요:
pip install -U langgraph더 나은 디버깅을 위해 LangSmith를 설정하세요
LangSmith에 가입하여 LangGraph 프로젝트의 문제를 빠르게 파악하고 성능을 개선하세요. LangSmith를 사용하면 추적 데이터를 통해 LangGraph로 구축한 LLM 앱을 디버깅, 테스트 및 모니터링할 수 있습니다. 시작하는 방법에 대한 자세한 내용은 문서를 참조하세요.
상태 정의 및 업데이트
여기서는 LangGraph에서 상태를 정의하고 업데이트하는 방법을 설명합니다. 다음을 보여드리겠습니다:
상태 정의
LangGraph의 상태는 TypedDict, Pydantic 모델 또는 데이터클래스가 될 수 있습니다. 아래에서는 TypedDict를 사용하겠습니다. Pydantic 사용에 대한 자세한 내용은 이 섹션을 참조하세요.
기본적으로 그래프는 입력과 출력 스키마가 동일하며, 상태가 해당 스키마를 결정합니다. 별도의 입력 및 출력 스키마를 정의하는 방법은 이 섹션을 참조하세요.
많은 LLM 애플리케이션에서 유용한 상태의 다용도 형식을 나타내는 메시지를 사용한 간단한 예를 살펴보겠습니다. 자세한 내용은 개념 페이지를 참조하세요.
API 참조: AnyMessage
from langchain_core.messages import AnyMessage
from typing_extensions import TypedDict
class State(TypedDict):
messages: list[AnyMessage]
extra_field: int이 상태는 메시지 객체 목록과 추가 정수 필드를 추적합니다.
상태 업데이트
단일 노드로 구성된 예제 그래프를 만들어보겠습니다. 노드는 그래프의 상태를 읽고 업데이트하는 Python 함수입니다. 이 함수의 첫 번째 인자는 항상 상태입니다:
API 참조: AIMessage
from langchain_core.messages import AIMessage
def node(state: State):
messages = state["messages"]
new_message = AIMessage("Hello!")
return {"messages": messages + [new_message], "extra_field": 10}이 노드는 단순히 메시지 목록에 메시지를 추가하고 추가 필드를 채웁니다.
중요
노드는 상태를 직접 변경하지 말고 상태 업데이트를 반환해야 합니다.
다음으로 이 노드를 포함하는 간단한 그래프를 정의하겠습니다. 이 상태에서 작동하는 그래프를 정의하려면 StateGraph를 사용합니다. 그런 다음 add_node를 사용하여 그래프를 채웁니다.
API 참조: StateGraph
from langgraph.graph import StateGraph
builder = StateGraph(State)
builder.add_node(node)
builder.set_entry_point("node")
graph = builder.compile()그래프를 시각화하는 기본 제공 유틸리티가 LangGraph에 있습니다. 그래프를 검사해보겠습니다. 시각화에 대한 자세한 내용은 이 섹션을 참조하세요.
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))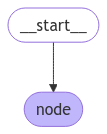
이 경우 그래프는 단일 노드만 실행합니다. 간단한 호출을 진행해보겠습니다:
API 참조: HumanMessage
from langchain_core.messages import HumanMessage
result = graph.invoke({"messages": [HumanMessage("Hi")]})
result{'messages': [HumanMessage(content='Hi'), AIMessage(content='Hello!')], 'extra_field': 10}다음 사항에 유의하세요:
- 호출을 시작할 때 상태의 단일 키를 업데이트했습니다.
- 호출 결과에서 전체 상태를 받습니다.
편의를 위해 메시지 객체의 내용을 예쁘게 출력으로 자주 검사합니다:
for message in result["messages"]:
message.pretty_print()리듀서를 사용하여 상태 업데이트 처리
상태의 각 키는 업데이트가 노드에서 어떻게 적용되는지 제어하는 독립적인 리듀서 함수를 가질 수 있습니다. 리듀서 함수가 명시적으로 지정되지 않으면 키에 대한 모든 업데이트가 이를 덮어쓰는 것으로 가정합니다.
TypedDict 상태 스키마의 경우 해당 상태 필드에 리듀서 함수를 주석으로 추가하여 리듀서를 정의할 수 있습니다.
앞선 예제에서 노드는 메시지를 추가하여 "messages" 키를 업데이트했습니다. 아래에서는 업데이트가 자동으로 추가되도록 이 키에 리듀서를 추가하겠습니다:
from typing_extensions import Annotated
def add(left, right):
"""빌트인 \`operator\`에서 \`add\`를 가져올 수도 있습니다."""
return left + right
class State(TypedDict):
messages: Annotated[list[AnyMessage], add]
extra_field: int이제 노드를 단순화할 수 있습니다:
def node(state: State):
new_message = AIMessage("Hello!")
return {"messages": [new_message], "extra_field": 10}API 참조: START
from langgraph.graph import START
graph = StateGraph(State).add_node(node).add_edge(START, "node").compile()
result = graph.invoke({"messages": [HumanMessage("Hi")]})
for message in result["messages"]:
message.pretty_print()MessagesState
메시지 목록을 업데이트할 때 추가적인 고려사항이 있습니다:
LangGraph에는 이러한 고려사항을 처리하는 기본 제공 리듀서 add_messages가 포함되어 있습니다:
API 참조: add_messages
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
extra_field: int
def node(state: State):
new_message = AIMessage("Hello!")
return {"messages": [new_message], "extra_field": 10}
graph = StateGraph(State).add_node(node).set_entry_point("node").compile()input_message = {"role": "user", "content": "Hi"}
result = graph.invoke({"messages": [input_message]})
for message in result["messages"]:
message.pretty_print()이는 채팅 모델과 관련된 애플리케이션에서 상태를 표현하는 다용도 방식입니다. 편의를 위해 LangGraph에는 사전 구축된 MessagesState가 포함되어 있어 다음과 같이 사용할 수 있습니다:
from langgraph.graph import MessagesState
class State(MessagesState):
extra_field: int입력 및 출력 스키마 정의
기본적으로 StateGraph는 단일 스키마로 작동하며 모든 노드가 해당 스키마를 사용하여 통신할 것으로 예상됩니다. 그러나 그래프에 대해 별개의 입력 및 출력 스키마를 정의할 수도 있습니다.
별개의 스키마가 지정되면 노드 간 통신에는 여전히 내부 스키마가 사용됩니다. 입력 스키마는 제공된 입력이 예상 구조와 일치하는지 확인하는 반면, 출력 스키마는 정의된 출력 스키마에 따라 관련 정보만 반환하도록 내부 데이터를 필터링합니다.
아래에서 별개의 입력 및 출력 스키마를 정의하는 방법을 살펴보겠습니다.
API 참조: StateGraph | START | END
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
# 입력 스키마 정의
class InputState(TypedDict):
question: str
# 출력 스키마 정의
class OutputState(TypedDict):
answer: str
# 입력과 출력을 모두 결합한 전체 스키마 정의
class OverallState(InputState, OutputState):
pass
# 입력을 처리하고 답변을 생성하는 노드 정의
def answer_node(state: InputState):
# 예시 답변과 추가 키
return {"answer": "bye", "question": state["question"]}
# 입력 및 출력 스키마가 지정된 그래프 구축
builder = StateGraph(OverallState, input_schema=InputState, output_schema=OutputState)
builder.add_node(answer_node) # 답변 노드 추가
builder.add_edge(START, "answer_node") # 시작 엣지 정의
builder.add_edge("answer_node", END) # 종료 엣지 정의
graph = builder.compile() # 그래프 컴파일
# 입력과 함께 그래프 호출하고 결과 출력
print(graph.invoke({"question": "hi"})){'answer': 'bye'}호출 출력에는 출력 스키마만 포함된다는 점에 유의하세요.
런타임 구성 추가
그래프를 호출할 때 구성할 수 있기를 원할 수 있습니다. 예를 들어, 그래프 상태에 이러한 매개변수를 오염시키지 않으면서 사용할 LLM이나 시스템 프롬프트를 런타임에 지정할 수 있기를 원할 수 있습니다.
런타임 구성을 추가하려면:
- 구성 스키마 지정
- 노드 또는 조건부 엣지의 함수 시그니처에 구성 추가
- 그래프에 구성 전달
아래에 간단한 예제가 있습니다:
API 참조: END | StateGraph | START
from langgraph.graph import END, StateGraph, START
from langgraph.runtime import Runtime
from typing_extensions import TypedDict
# 1. 구성 스키마 지정
class ContextSchema(TypedDict):
my_runtime_value: str
# 2. 노드에서 구성을 액세스하는 그래프 정의
class State(TypedDict):
my_state_value: str
def node(state: State, runtime: Runtime[ContextSchema]):
if runtime.context["my_runtime_value"] == "a":
return {"my_state_value": 1}
elif runtime.context["my_runtime_value"] == "b":
return {"my_state_value": 2}
else:
raise ValueError("알 수 없는 값입니다.")
builder = StateGraph(State, context_schema=ContextSchema)
builder.add_node(node)
builder.add_edge(START, "node")
builder.add_edge("node", END)
graph = builder.compile()
# 3. 런타임에 구성 전달:
print(graph.invoke({}, context={"my_runtime_value": "a"}))
print(graph.invoke({}, context={"my_runtime_value": "b"})){'my_state_value': 1}
{'my_state_value': 2}재시도 정책 추가
API 호출, 데이터베이스 쿼리, LLM 호출 등에서 노드에 사용자 정의 재시도 정책을 적용하고 싶을 수 있는 많은 사용 사례가 있습니다. LangGraph를 사용하면 노드에 재시도 정책을 추가할 수 있습니다.
재시도 정책을 구성하려면 add_node에 retry_policy 매개변수를 전달하세요. retry_policy 매개변수는 RetryPolicy 명명된 튜플 객체를 받습니다. 아래에서는 기본 매개변수로 RetryPolicy 객체를 인스턴스화하고 노드와 연결합니다:
API 참조: RetryPolicy
기본적으로 retry_on 매개변수는 default_retry_on 함수를 사용하며, 다음을 제외한 모든 예외에 대해 재시도합니다:
ValueErrorTypeErrorArithmeticErrorImportErrorLookupErrorNameErrorSyntaxErrorRuntimeErrorReferenceErrorStopIterationStopAsyncIterationOSError
또한 requests 및 httpx와 같은 인기 있는 HTTP 요청 라이브러리의 예외의 경우 5xx 상태 코드에서만 재시도합니다.
확장 예제: 재시도 정책 사용자 정의
SQL 데이터베이스에서 읽기를 수행하는 예제를 살펴보겠습니다. 아래에서는 두 노드에 서로 다른 재시도 정책을 전달합니다:
import sqlite3
from typing_extensions import TypedDict
from langchain.chat_models import init_chat_model
from langgraph.graph import END, MessagesState, StateGraph, START
from langgraph.types import RetryPolicy
from langchain_community.utilities import SQLDatabase
from langchain_core.messages import AIMessage
db = SQLDatabase.from_uri("sqlite:///:memory:")
model = init_chat_model("anthropic:claude-3-5-haiku-latest")
def query_database(state: MessagesState):
query_result = db.run("SELECT * FROM Artist LIMIT 10;")
return {"messages": [AIMessage(content=query_result)]}
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": [response]}
# 새 그래프 정의
builder = StateGraph(MessagesState)
builder.add_node(
"query_database",
query_database,
retry_policy=RetryPolicy(retry_on=sqlite3.OperationalError),
)
builder.add_node("model", call_model, retry_policy=RetryPolicy(max_attempts=5))
builder.add_edge(START, "model")
builder.add_edge("model", "query_database")
builder.add_edge("query_database", END)
graph = builder.compile()노드 캐싱 추가
노드 캐싱은 시간이나 비용 측면에서 비싼 작업을 반복하지 않으려는 경우에 유용합니다. LangGraph를 사용하면 그래프의 노드에 개별화된 캐싱 정책을 추가할 수 있습니다.
캐시 정책을 구성하려면 add_node 함수에 cache_policy 매개변수를 전달하세요. 다음 예제에서는 120초의 TTL과 기본 key_func 생성기로 CachePolicy 객체를 인스턴스화한 다음 노드와 연결합니다:
그런 다음 그래프를 컴파일할 때 cache 인자를 설정하여 그래프의 노드 수준 캐싱을 활성화하세요. 아래 예제에서는 메모리 내 캐시를 설정하기 위해 InMemoryCache를 사용하지만 SqliteCache도 사용할 수 있습니다.
from langgraph.cache.memory import InMemoryCache
graph = builder.compile(cache=InMemoryCache())단계 시퀀스 생성
전제 조건
이 가이드는 위의 상태 섹션에 익숙하다고 가정합니다.
여기서는 간단한 단계 시퀀스를 구성하는 방법을 보여드리겠습니다. 다음을 설명하겠습니다:
- 시퀀셜 그래프를 구축하는 방법
- 유사한 그래프를 구성하는 기본 제공 단축키
노드 시퀀스를 추가하려면 그래프의 .add_node 및 .add_edge 메서드를 사용합니다:
API 참조: START | StateGraph
기본 제공 단축키 .add_sequence도 사용할 수 있습니다:
builder = StateGraph(State).add_sequence([step_1, step_2, step_3])
builder.add_edge(START, "step_1")LangGraph로 애플리케이션 단계를 시퀀스로 분할하는 이유는 무엇일까요?
LangGraph를 사용하면 애플리케이션에 기본 지속성 계층을 쉽게 추가할 수 있습니다. 이를 통해 노드 실행 사이에 상태를 체크포인트할 수 있으므로 LangGraph 노드가 다음을 관리합니다:
또한 실행 단계가 스트리밍되는 방식과 LangGraph Studio를 사용하여 애플리케이션이 시각화되고 디버깅되는 방식을 결정합니다.
종단간 예제를 보여드리겠습니다. 세 단계의 시퀀스를 만들겠습니다:
- 상태 키의 값을 채우기
- 동일한 값 업데이트
- 다른 값 채우기
먼저 상태를 정의하겠습니다. 이는 그래프의 스키마를 관리하며 업데이트가 어떻게 적용되는지 지정할 수도 있습니다. 자세한 내용은 이 섹션을 참조하세요.
이 경우 두 값만 추적하겠습니다:
from typing_extensions import TypedDict
class State(TypedDict):
value_1: str
value_2: int노드는 그래프의 상태를 읽고 업데이트하는 Python 함수입니다. 이 함수의 첫 번째 인자는 항상 상태입니다:
def step_1(state: State):
return {"value_1": "a"}
def step_2(state: State):
current_value_1 = state["value_1"]
return {"value_1": f"{current_value_1} b"}
def step_3(state: State):
return {"value_2": 10}참고
상태를 업데이트할 때 각 노드는 업데이트하려는 키의 값만 지정하면 됩니다.
기본적으로 이는 해당 키의 값을 덮어씁니다. 업데이트가 처리되는 방식을 제어하려면 리듀서를 사용할 수도 있습니다. 예를 들어 키에 대한 연속 업데이트를 추가할 수 있습니다. 자세한 내용은 이 섹션을 참조하세요.
마지막으로 그래프를 정의하겠습니다. 이 상태에서 작동하는 그래프를 정의하려면 StateGraph를 사용합니다.
그런 다음 add_node와 add_edge를 사용하여 그래프를 채우고 제어 흐름을 정의하겠습니다.
API 참조: START | StateGraph
사용자 정의 이름 지정
.add_node를 사용하여 노드에 사용자 정의 이름을 지정할 수 있습니다:
builder.add_node("my_node", step_1)다음 사항에 유의하세요:
.add_edge는 함수의 경우 기본적으로node.__name__인 노드 이름을 받습니다.- 그래프의 진입점을 지정해야 합니다. 이를 위해 START 노드와 엣지를 추가합니다.
- 더 이상 실행할 노드가 없으면 그래프가 중단됩니다.
다음으로 그래프를 컴파일하겠습니다. 이는 그래프 구조에 대한 몇 가지 기본 검사를 제공합니다(예: 고아 노드 식별). 체크포인터를 통해 애플리케이션에 지속성을 추가하는 경우 여기에도 전달됩니다.
graph = builder.compile()그래프를 시각화하는 기본 제공 유틸리티가 LangGraph에 있습니다. 시퀀스를 검사해보겠습니다. 시각화에 대한 자세한 내용은 이 가이드를 참조하세요.
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))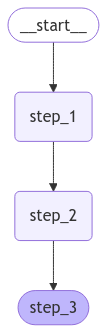
간단한 호출을 진행해보겠습니다:
graph.invoke({"value_1": "c"}){'value_1': 'a b', 'value_2': 10}다음 사항에 유의하세요:
- 단일 상태 키에 대한 값만 제공하여 호출을 시작했습니다. 최소 하나의 키에 대한 값을 항상 제공해야 합니다.
- 전달한 값은 첫 번째 노드에 의해 덮어쓰여졌습니다.
- 두 번째 노드가 값을 업데이트했습니다.
- 세 번째 노드가 다른 값을 채웠습니다.
기본 제공 단축키
langgraph>=0.2.46에는 노드 시퀀스를 추가하기 위한 기본 제공 단축키 add_sequence가 포함되어 있습니다. 다음과 같이 동일한 그래프를 컴파일할 수 있습니다:
builder = StateGraph(State).add_sequence([step_1, step_2, step_3])
graph = builder.compile()
graph.invoke({"value_1": "c"})브랜치 생성
노드를 병렬로 실행하는 것은 전체 그래프 작업 속도를 높이는 데 필수적입니다. LangGraph는 표준 엣지와 조건부 엣지를 모두 활용한 팬아웃 및 팬인 메커니즘을 통해 노드의 병렬 실행을 기본적으로 지원합니다. 이를 통해 그래프 기반 워크플로의 성능을 크게 향상시킬 수 있습니다. 다음은 사용자에게 적합한 분기 데이터플로를 생성하는 방법에 대한 몇 가지 예제입니다.
그래프 노드를 병렬로 실행
이 예제에서는 Node A에서 B와 C로 팬아웃한 다음 D로 팬인합니다. 상태와 함께 리듀서 add 작업을 지정합니다. 이는 단순히 기존 값을 덮어쓰지 않고 특정 키의 값을 결합하거나 누적합니다. 목록의 경우 새 목록을 기존 목록과 연결합니다. 리듀서를 사용하여 상태를 업데이트하는 방법에 대한 자세한 내용은 위의 상태 리듀서 섹션을 참조하세요.
API 참조: StateGraph | START | END
import operator
from typing import Annotated, Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
# operator.add 리듀서 함수를 사용하면 추가 전용이 됩니다
aggregate: Annotated[list, operator.add]
def a(state: State):
print(f'집계에 "A" 추가 중 {state["aggregate"]}')
return {"aggregate": ["A"]}
def b(state: State):
print(f'집계에 "B" 추가 중 {state["aggregate"]}')
return {"aggregate": ["B"]}
def c(state: State):
print(f'집계에 "C" 추가 중 {state["aggregate"]}')
return {"aggregate": ["C"]}
def d(state: State):
print(f'집계에 "D" 추가 중 {state["aggregate"]}')
return {"aggregate": ["D"]}
builder = StateGraph(State)
builder.add_node(a)
builder.add_node(b)
builder.add_node(c)
builder.add_node(d)
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))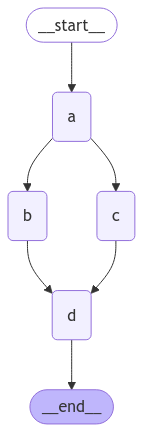
리듀서를 사용하면 각 노드에서 추가된 값이 누적되는 것을 확인할 수 있습니다.
graph.invoke({"aggregate": []}, {"configurable": {"thread_id": "foo"}})집계에 "A" 추가 중 []
집계에 "B" 추가 중 ['A']
집계에 "C" 추가 중 ['A']
집계에 "D" 추가 중 ['A', 'B', 'C']참고
위 예제에서 노드 "b"와 "c"는 동일한 슈퍼스텝에서 동시에 실행됩니다. 동일한 단계에 있기 때문에 노드 "d"는 "b"와 "c"가 모두 완료된 후에 실행됩니다.
중요하게도 병렬 슈퍼스텝의 업데이트는 일관되게 정렬되지 않을 수 있습니다. 병렬 슈퍼스텝에서 업데이트의 일관되고 미리 결정된 순서가 필요한 경우 별도의 필드에 출력과 함께 순서를 지정하는 값을 작성해야 합니다.
예외 처리?
LangGraph는 슈퍼스텝 내에서 노드를 실행합니다. 즉, 병렬 브랜치가 병렬로 실행되지만 전체 슈퍼스텝은 트랜잭션입니다. 이러한 브랜치 중 하나가 예외를 발생시키면 업데이트가 상태에 적용되지 않습니다(전체 슈퍼스텝이 오류 발생).
중요하게는 체크포인터를 사용할 때 슈퍼스텝 내 성공한 노드의 결과가 저장되며 재개 시 반복되지 않습니다.
오류가 발생하기 쉬운 경우(예: 불안정한 API 호출을 처리하려는 경우) LangGraph는 이를 해결하는 두 가지 방법을 제공합니다:
- 노드 내에서 일반 Python 코드를 작성하여 예외를 포착하고 처리할 수 있습니다.
- **재시도 정책**을 설정하여 그래프가 특정 유형의 예외를 발생시키는 노드를 재시도하도록 지시할 수 있습니다. 실패한 브랜치만 재시도되므로 중복 작업을 수행할 필요가 없습니다.
이를 통해 병렬 실행을 수행하고 예외 처리를 완전히 제어할 수 있습니다.
맵-리듀스 및 Send API
LangGraph는 Send API를 사용하여 맵-리듀스 및 기타 고급 브랜치 패턴을 지원합니다. 사용하는 방법의 예는 다음과 같습니다:
API 참조: StateGraph | START | END | Send
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
from typing_extensions import TypedDict, Annotated
import operator
class OverallState(TypedDict):
topic: str
subjects: list[str]
jokes: Annotated[list[str], operator.add]
best_selected_joke: str
def generate_topics(state: OverallState):
return {"subjects": ["lions", "elephants", "penguins"]}
def generate_joke(state: OverallState):
joke_map = {
"lions": "Why don't lions like fast food? Because they can't catch it!",
"elephants": "Why don't elephants use computers? They're afraid of the mouse!",
"penguins": "Why don't penguins like talking to strangers at parties? Because they find it hard to break the ice."
}
return {"jokes": [joke_map[state["subject"]]]}
def continue_to_jokes(state: OverallState):
return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]
def best_joke(state: OverallState):
return {"best_selected_joke": "penguins"}
builder = StateGraph(OverallState)
builder.add_node("generate_topics", generate_topics)
builder.add_node("generate_joke", generate_joke)
builder.add_node("best_joke", best_joke)
builder.add_edge(START, "generate_topics")
builder.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])
builder.add_edge("generate_joke", "best_joke")
builder.add_edge("best_joke", END)
graph = builder.compile()from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))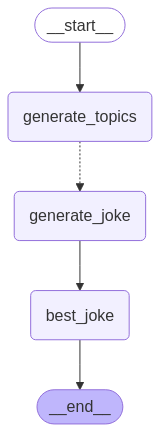
# 그래프 호출: 여기서는 농담 목록을 생성하도록 호출합니다
for step in graph.stream({"topic": "animals"}):
print(step){'generate_topics': {'subjects': ['lions', 'elephants', 'penguins']}}
{'generate_joke': {'jokes': ["Why don't lions like fast food? Because they can't catch it!"]}}
{'generate_joke': {'jokes': ["Why don't elephants use computers? They're afraid of the mouse!"]}}
{'generate_joke': {'jokes': ['Why don't penguins like talking to strangers at parties? Because they find it hard to break the ice.']}}
{'best_joke': {'best_selected_joke': 'penguins'}}루프 생성 및 제어
루프가 있는 그래프를 생성할 때 실행을 종료하는 메커니즘이 필요합니다. 이는 일반적으로 종료 조건에 도달하면 END 노드로 라우팅하는 조건부 엣지를 추가하여 수행됩니다.
그래프 호출 또는 스트리밍 시 그래프 재귀 제한을 설정할 수도 있습니다. 재귀 제한은 오류를 발생시키기 전에 그래프가 실행할 수 있는 슈퍼스텝 수를 설정합니다. 재귀 제한 개념에 대한 자세한 내용은 여기를 참조하세요.
간단한 루프가 있는 그래프를 통해 이러한 메커니즘이 어떻게 작동하는지 더 잘 이해해보겠습니다.
팁
재귀 제한 오류 대신 상태의 마지막 값을 반환하려면 다음 섹션을 참조하세요.
루프를 생성할 때 종료 조건을 지정하는 조건부 엣지를 포함할 수 있습니다:
builder = StateGraph(State)
builder.add_node(a)
builder.add_node(b)
def route(state: State) -> Literal["b", END]:
if termination_condition(state):
return END
else:
return "b"
builder.add_edge(START, "a")
builder.add_conditional_edges("a", route)
builder.add_edge("b", "a")
graph = builder.compile()재귀 제한을 제어하려면 구성에서 "recursionLimit"을 지정하세요. 이는 지정된 수의 슈퍼스텝 후에 GraphRecursionError를 발생시킵니다. 그런 다음 이를 포착하고 처리할 수 있습니다:
from langgraph.errors import GraphRecursionError
try:
graph.invoke(inputs, {"recursion_limit": 3})
except GraphRecursionError:
print("재귀 오류")종료 조건을 지정하는 조건부 엣지를 사용하여 간단한 루프가 있는 그래프를 정의하겠습니다.
API 참조: StateGraph | START | END
import operator
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
# operator.add 리듀서 함수를 사용하면 추가 전용이 됩니다
aggregate: Annotated[list, operator.add]
def a(state: State):
print(f'노드 A가 {state["aggregate"]}를 확인함')
return {"aggregate": ["A"]}
def b(state: State):
print(f'노드 B가 {state["aggregate"]}를 확인함')
return {"aggregate": ["B"]}
# 노드 정의
builder = StateGraph(State)
builder.add_node(a)
builder.add_node(b)
# 엣지 정의
def route(state: State) -> Literal["b", END]:
if len(state["aggregate"]) < 7:
return "b"
else:
return END
builder.add_edge(START, "a")
builder.add_conditional_edges("a", route)
builder.add_edge("b", "a")
graph = builder.compile()from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))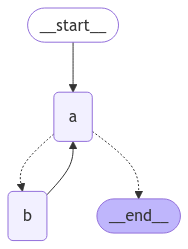
이 아키텍처는 노드 "a"가 도구 호출 모델이고 노드 "b"가 도구를 나타내는 React 에이전트와 유사합니다.
route 조건부 엣지에서 상태의 "aggregate" 목록이 임계값 길이를 초과하면 종료하도록 지정합니다.
그래프를 호출하면 종료 조건에 도달할 때까지 노드 "a"와 "b"를 번갈아 실행하는 것을 확인할 수 있습니다.
graph.invoke({"aggregate": []})노드 A가 []를 확인함
노드 B가 ['A']를 확인함
노드 A가 ['A', 'B']를 확인함
노드 B가 ['A', 'B', 'A']를 확인함
노드 A가 ['A', 'B', 'A', 'B']를 확인함
노드 B가 ['A', 'B', 'A', 'B', 'A']를 확인함
노드 A가 ['A', 'B', 'A', 'B', 'A', 'B']를 확인함비동기
비동기 프로그래밍 패러다임을 사용하면 IO 바운드 코드(예: 채팅 모델 제공업체에 대한 동시 API 요청)를 동시에 실행할 때 상당한 성능 향상을 얻을 수 있습니다.
sync 구현을 async 구현으로 변환하려면:
- 노드에서
async def대신def를 사용하도록 업데이트합니다. - 적절히
await를 사용하도록 내부 코드 업데이트합니다. .ainvoke또는.astream으로 그래프를 호출합니다.
많은 LangChain 객체가 모든 sync 메서드의 async 변형을 포함하는 Runnable Protocol을 구현하므로 일반적으로 sync 그래프를 async 그래프로 업그레이드하는 데 상당히 빠릅니다.
아래 예제를 참조하세요. 기본 LLM의 비동기 호출을 시연하기 위해 채팅 모델을 포함하겠습니다:
API 참조: init_chat_model | StateGraph
from langchain.chat_models import init_chat_model
from langgraph.graph import MessagesState, StateGraph
async def node(state: MessagesState):
new_message = await llm.ainvoke(state["messages"])
return {"messages": [new_message]}
builder = StateGraph(MessagesState).add_node(node).set_entry_point("node")
graph = builder.compile()
input_message = {"role": "user", "content": "Hello"}
result = await graph.ainvoke({"messages": [input_message]})비동기 스트리밍
비동기로 스트리밍하는 예제는 스트리밍 가이드를 참조하세요.
Command를 사용하여 제어 흐름과 상태 업데이트 결합
제어 흐름(엣지)과 상태 업데이트(노드)를 결합하는 것이 유용할 수 있습니다. 예를 들어, 상태 업데이트를 수행하고 동시에 다음에 이동할 노드를 결정하는 노드에서 모두 수행하고 싶을 수 있습니다. LangGraph는 노드 함수에서 Command 객체를 반환하여 이를 수행하는 방법을 제공합니다:
def my_node(state: State) -> Command[Literal["my_other_node"]]:
return Command(
# 상태 업데이트
update={"foo": "bar"},
# 제어 흐름
goto="my_other_node"
)아래에서 종단간 예제를 보여드리겠습니다. 3개의 노드 A, B, C가 있는 간단한 그래프를 만들겠습니다. 먼저 노드 A를 실행한 다음 노드 A의 출력에 따라 다음에 노드 B 또는 노드 C로 이동할지 결정하겠습니다.
API 참조: StateGraph | START | Command
import random
from typing_extensions import TypedDict, Literal
from langgraph.graph import StateGraph, START
from langgraph.types import Command
# 그래프 상태 정의
class State(TypedDict):
foo: str
# 노드 정의
def node_a(state: State) -> Command[Literal["node_b", "node_c"]]:
print("A 호출됨")
value = random.choice(["b", "c"])
# 이는 조건부 엣지 함수의 대체입니다
if value == "b":
goto = "node_b"
else:
goto = "node_c"
# Command를 사용하면 그래프 상태를 업데이트하고 다음 노드로 라우팅할 수 있습니다
return Command(
# 이는 상태 업데이트입니다
update={"foo": value},
# 이는 엣지의 대체입니다
goto=goto,
)
def node_b(state: State):
print("B 호출됨")
return {"foo": state["foo"] + "b"}
def node_c(state: State):
print("C 호출됨")
return {"foo": state["foo"] + "c"}이제 위 노드로 StateGraph를 생성할 수 있습니다. 그래프에 조건부 엣지가 없다는 점에 유의하세요! 이는 제어 흐름이 node_a 내부의 Command로 정의되기 때문입니다.
builder = StateGraph(State)
builder.add_edge(START, "node_a")
builder.add_node(node_a)
builder.add_node(node_b)
builder.add_node(node_c)
# 참고: 노드 A, B, C 간에는 엣지가 없습니다!
graph = builder.compile()중요
Command[Literal["node_b", "node_c"]]처럼Command를 반환 타입 주석으로 사용했다는 점에 유의할 수 있습니다. 이는 그래프 렌더링에 필요하며node_a가node_b와node_c로 이동할 수 있음을 LangGraph에 알려줍니다.
from IPython.display import display, Image
display(Image(graph.get_graph().draw_mermaid_png()))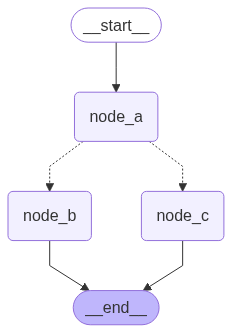
그래프를 여러 번 실행하면 노드 A의 무작위 선택에 따라 다른 경로(A → B 또는 A → C)를 취하는 것을 확인할 수 있습니다.
graph.invoke({"foo": ""})A 호출됨
C 호출됨그래프 시각화
생성한 그래프를 시각화하는 방법을 보여드리겠습니다.
임의의 Graph를 시각화할 수 있습니다( StateGraph 포함).
프랙탈을 그려서 재미있게 해보겠습니다 :).
API 참조: StateGraph | START | END | add_messages
import random
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
class MyNode:
def __init__(self, name: str):
self.name = name
def __call__(self, state: State):
return {"messages": [("assistant", f"노드 {self.name} 호출됨")]}
def route(state) -> Literal["entry_node", "__end__"]:
if len(state["messages"]) > 10:
return "__end__"
return "entry_node"
def add_fractal_nodes(builder, current_node, level, max_level):
if level > max_level:
return
# 이 수준에서 생성할 노드 수
num_nodes = random.randint(1, 3) # 필요에 따라 무작위성 조정
for i in range(num_nodes):
nm = ["A", "B", "C"][i]
node_name = f"node_{current_node}_{nm}"
builder.add_node(node_name, MyNode(node_name))
builder.add_edge(current_node, node_name)
# 더 많은 노드를 재귀적으로 추가
r = random.random()
if r > 0.2 and level + 1 < max_level:
add_fractal_nodes(builder, node_name, level + 1, max_level)
elif r > 0.05:
builder.add_conditional_edges(node_name, route, node_name)
else:
# 종료
builder.add_edge(node_name, "__end__")
def build_fractal_graph(max_level: int):
builder = StateGraph(State)
entry_point = "entry_node"
builder.add_node(entry_point, MyNode(entry_point))
builder.add_edge(START, entry_point)
add_fractal_nodes(builder, entry_point, 1, max_level)
# 필요시 완료 지점 설정
builder.add_edge(entry_point, END) # 또는 특정 노드
return builder.compile()
app = build_fractal_graph(3)Mermaid
그래프 클래스를 Mermaid 구문으로 변환할 수도 있습니다.
print(app.get_graph().draw_mermaid())PNG
원하는 경우 그래프를 .png로 렌더링할 수 있습니다. 여기서는 세 가지 옵션을 사용할 수 있습니다:
- Mermaid.ink API 사용(추가 패키지 불필요)
- Mermaid + Pyppeteer 사용(
pip install pyppeteer필요) - graphviz 사용(
pip install graphviz필요)
Mermaid.Ink 사용
기본적으로 draw_mermaid_png()는 Mermaid.Ink의 API를 사용하여 다이어그램을 생성합니다.
API 참조: CurveStyle | MermaidDrawMethod | NodeStyles
from IPython.display import Image, display
from langchain_core.runnables.graph import CurveStyle, MermaidDrawMethod, NodeStyles
display(Image(app.get_graph().draw_mermaid_png()))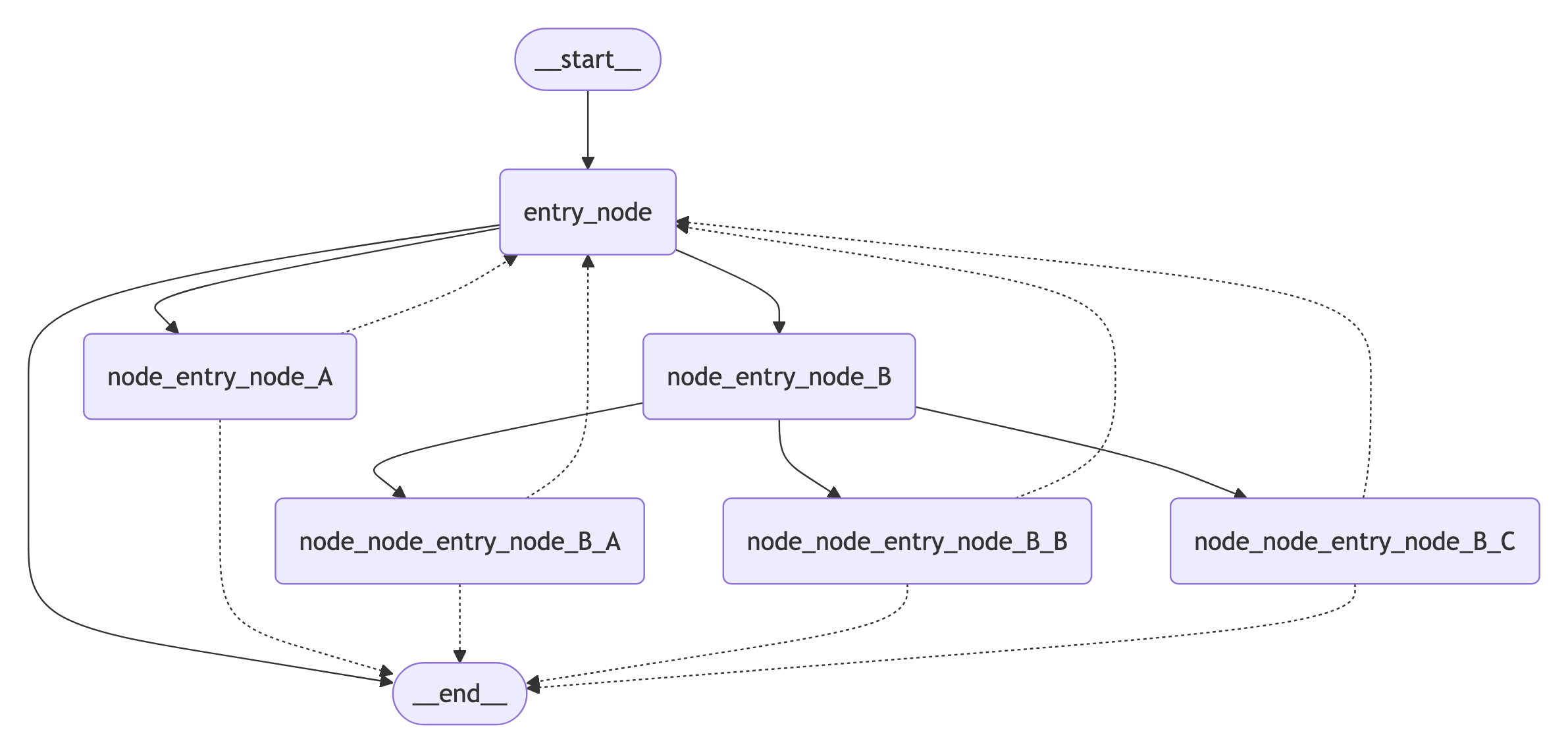
Mermaid + Pyppeteer 사용
Graphviz 사용
try:
display(Image(app.get_graph().draw_png()))
except ImportError:
print(
"pygraphviz의 종속성을 설치해야 할 수 있습니다. 자세한 내용은 https://github.com/pygraphviz/pygraphviz/blob/main/INSTALL.txt를 참조하세요"
)